Coreference chains in research articles (master thesis)
I have two French master degrees:
- one in language technologies (Technologies des langues),
- and one in French linguistics (Sciences du langage).
I have thus written two master theses. This page summarizes the second one: a linguistic study of coreference chain in IMRaD research articles. For the other one (a rule-based automatic coreference resolution tool), read here.
The thesis is entitled Étude des chaînes de référence dans les articles de recherche de format IMRaD: problèmes d'annotation, analyse quantitative et qualitative (Coreference chains in IMRaD papers: annotation and analysis).
Part of it has been published in a scientific paper (in French): Types de chaînes de référence dans les articles de recherche de format IMRaD, Discours: A journal of linguistics, psycholinguistics and computational linguistics, 25 (2020).
The work has also been presented during the workshop “Référence, coréférence et structure textuelle”, November the 27th, 2017, École Normale Supérieur, Lyon.
read the thesis (194 pages) read the paper read the slides
Both theses are related to coreference chains. A coreference chain is the set of all expressions of a text that refer to the same referent (referring expressions). For example, all the expressions in bold in the following text refer to the same entity "Sophia Loren":
[Sophia Loren] says [she] will always be grateful to Bono. [The actress] revealed that the U2 singer helped [her] calm down when [she] became scared by a thunderstorm while travelling on a plane. (This example is from Mitkov's Anaphora Resolution book.)
There is a second chain for the entity "Bono".
Each expression that is part of a coreference chain is called a mention.
Many research articles in experimental sciences present a standardized form known as the IMRaD format, an acronym for “Introduction, Methods, Results and Discussion”. Each of these sections has a specific purpose (presenting the framework, describing the methodology, reporting the results and then discussing them), but also specific linguistic features. My goal was to see how coreference chains differ in each of these sections.
The thesis opens with a discussion about the concepts of referring expression and coreference, questionning annotation of abstract entities, predicates (in their nominal, verbal and adjectivale forms), etc. Are these referring expressions? For instance, is justice a referring expression? Are two abstracts synonyms (the death of Caesar, the murder of Caesar) coreferent?
To build the corpus, I analyzed 22,000 papers automatically downloaded from various academic journals (web scrapping) in order to described the place of IMRaD papers in the French research landscape (chapter 2 of the thesis).
I defined annotation guidelines for coreference annotation (chapter 4 of the thesis).
I annotated on my own a corpus of 35,000 tokens with 3,000 mentions (chapter 5 and 6 of the thesis).
I developed a tool in Perl to analyze the data, which later became CRViewer, a tool in Java.
I established a first typology of coreference chains (summarized in the workshop and Discours paper):
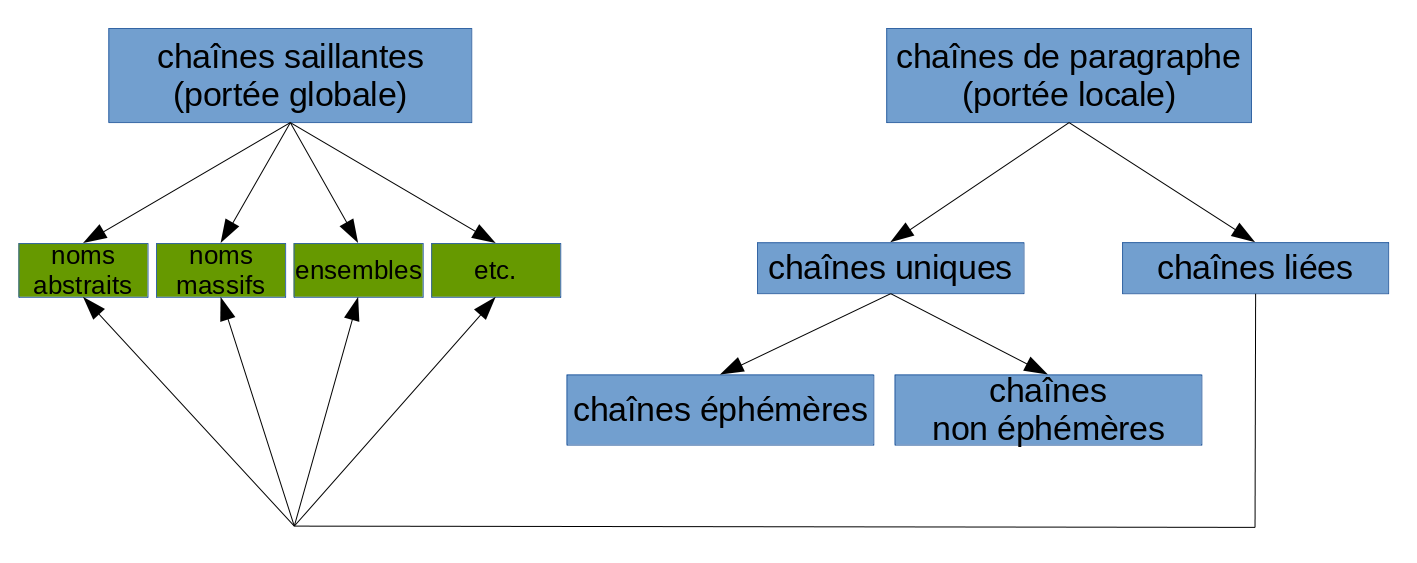
I confirmed my hypothesis that coreference chain varies according to the IMRaD section that appear in (chapters 5 and 6 of the thesis, Discours paper) (click to enlarge):


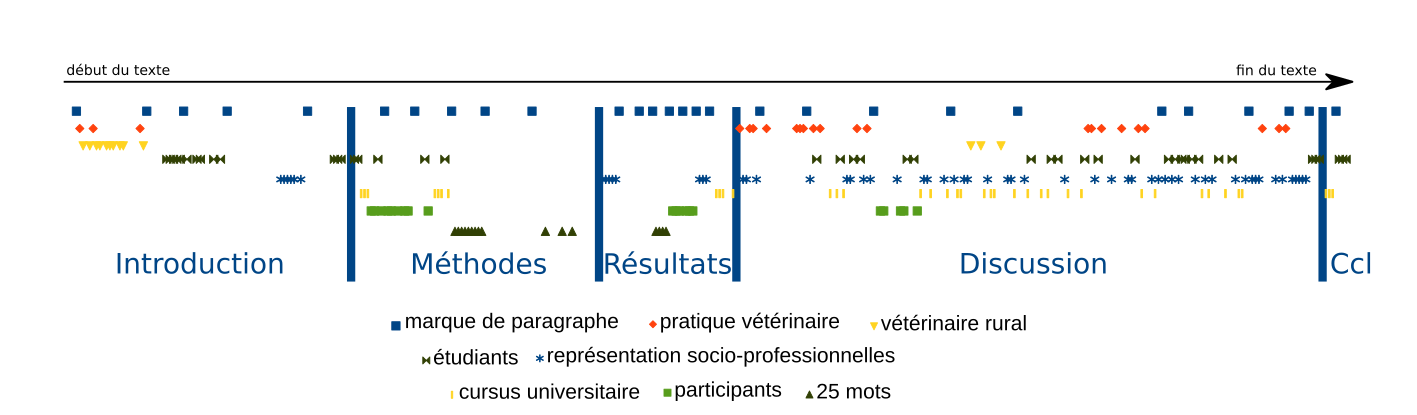
Distribution of mentions in the IMRaD sections of one of the text
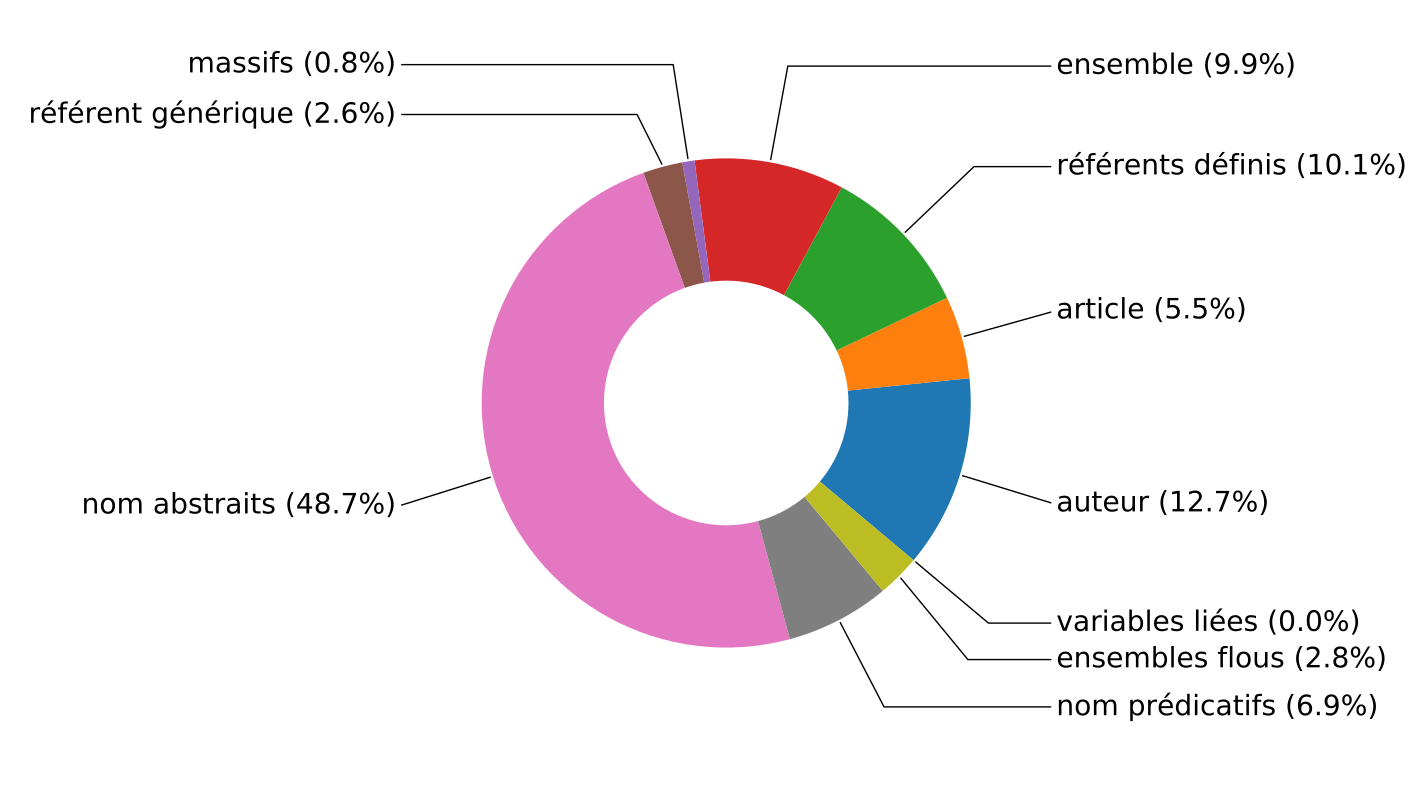
Example (from the paper): Distribution of mentions in the Introduction section by types of referents
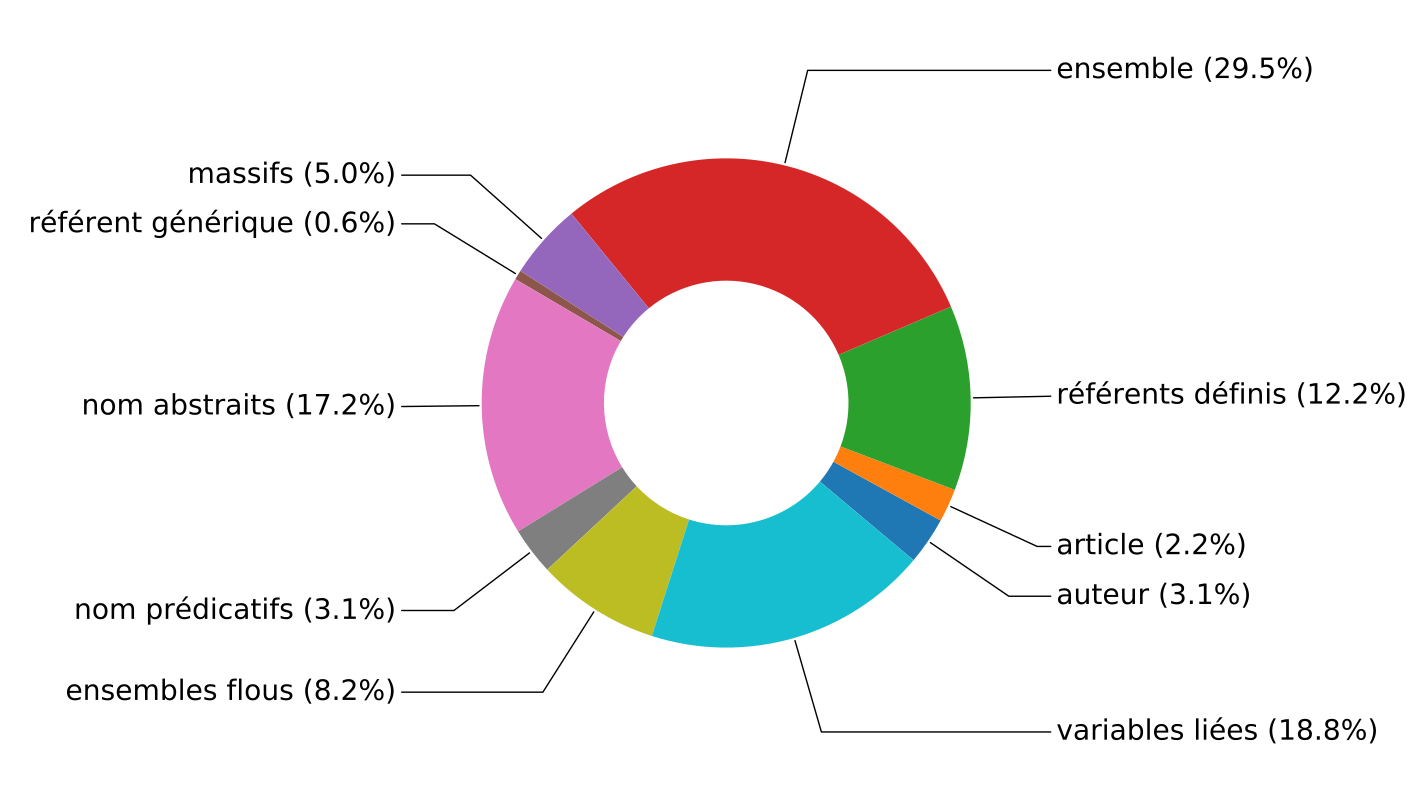
Example (from the paper): Distribution of mentions in the Methods section by types of referents
read full the thesis (in French)
To see the other master thesis: A rule-based automatic coreference resolution tool.