Les chaînes de coréférence dans les articles scientifiques (mémoire de master)
J'ai deux masters (M2) de l'Université de Strasbourg:
- l'un en Linguistique, Informatique, Traduction (actuellement nommé “Technologies des langues”),
- et l'un en Sciences du langage.
J'ai donc écrit deux mémoires. Cette page résume le second: Étude des chaînes de référence dans les articles de recherche de format IMRaD: problèmes d'annotation, analyse quantitative et qualitative. Pour le premier (ODACR: un Outil de Détection Automatique des Chaînes de Référence à base de règles linguistiques), lire ici.
Une partie du travail a été publié dans un article scientifique: Types de chaînes de référence dans les articles de recherche de format IMRaD, Discours: Revue de linguistique, psycholinguistique et informatique, 25 (2020).
Il a aussi été présenté lors de la journée d'études “Référence, coréférence et structure textuelle”, du 27 novembre 2017 à l'École Nationale Supérieure de Lyon.
lire le mémoire (194 pages) lire l'article voir les slides
Les deux mémoires portent sur les chaînes de coréférence. Une chaînes de coréférence est l'ensemble de toutes les expressions d'un texte qui renvoient au même référent (expressions référentielles). Par exemple, toutes les expressions en gras dans le texte suivant renvoient à la même entité "Platon":
[Platon] est un philosophe antique de la Grèce classique... [Il] reprit le travail philosophique de certains de [ses] prédécesseurs, notamment Socrate dont [il] fut l'élève (extrait de Wikipédia).
Chaque expression qui fait partie d'une chaîne de référence est appelée une mention.
Dans l'un des travaux, j'ai développé un système de résolution automatique de la coréférence à partir de règles linguistiques. Dans le second, j'ai étudié, dans la perspective d'une analyse de corpus, les chaînes de coréférence dans les articles de format IMRaD (plus d'informations ci-dessous).
La plupart des articles de recherche en sciences expérimentales présentent un format standardisé, dit « IMRaD » (Introduction, Méthodes, Résultats et Discussion). Chacune de ces parties remplit une fonction spécifique (présenter le cadre de la recherche, décrire les méthodes, rapporter les observations, et les discuter) qui est marquée par une variation de certains phénomènes linguistiques. Mon objectif était de voir comme les chaînes de coréférence se comporte dans chacune de ces section.
Le mémoire s'ouvre sur une réflexion sur la notion d'expression référentielle et de coréférence, en s'interrogeant sur la nécessité d'annotation des entités abstraits, des prédicats (dans leur forme nominale, verbale, adjectivale), etc. Sont-ce des expressions référentielles? Par exemple, justice est-il une expression référentielle? Deux synonymes abstraits (la mort de César, l'assassinat de César) sont-ils coréférents?
Pour la constitution du corpus, j'ai analysé 22 000 articles, qui ont été automatiquement récupérés sur plusieurs revues scientifiques en lignes (web scrapping) afin de dresser un panorama du format IMRaD dans les paysages des articles écrits en français (chapitre 2 du mémoire).
J'ai défini un guide d'annotation pour l'annotation de la coréférence (chapitre 4 du mémoire).
J'ai annoté moi-même un corpus de 35 000 tokens contenant 3 000 mentions (chapitres 5 et 6 du mémoire).
J'ai développé des outils d'analyse en Perl, qui sont devenus ensuite l'outil Java CRViewer.
J'ai établi une première typologie des chaînes de coréférence (résumée dans le workshop et l'article de Discours):
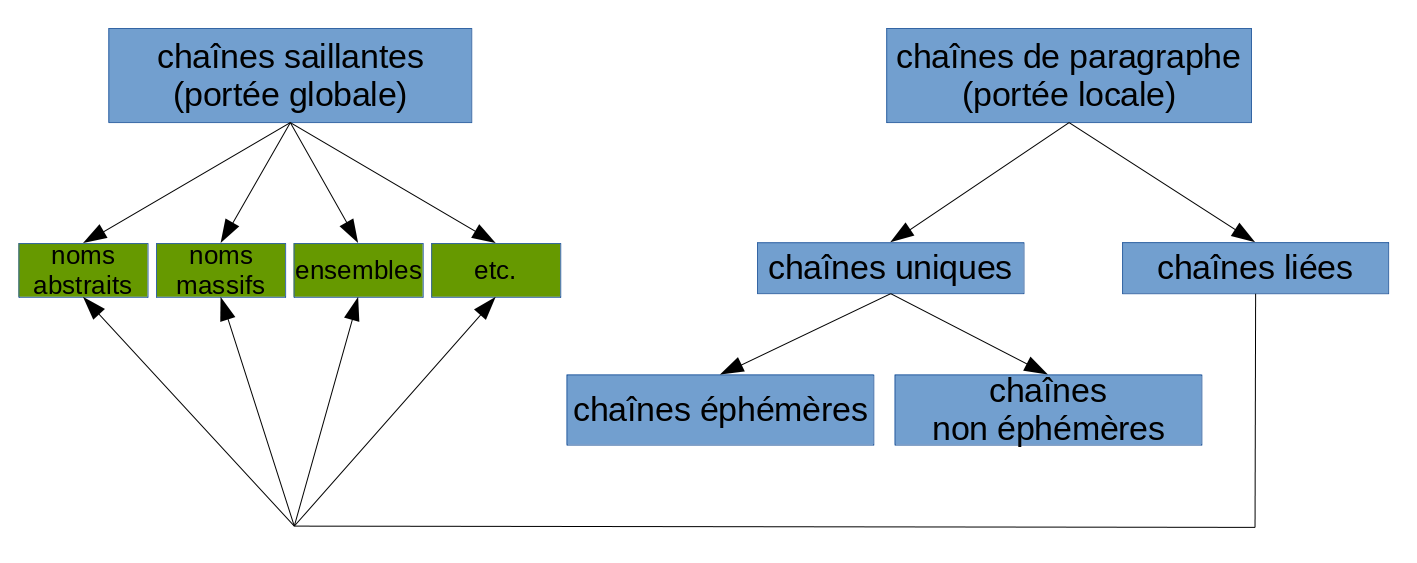
J'ai confirmé mon hypothèse que les chaînes de coréférence varient en fonction de la section IMRaD dans laquelle elles apparaissent (chapitres 5 et 6 du mémoire, article de Discours) (cliquer pour agrandir):


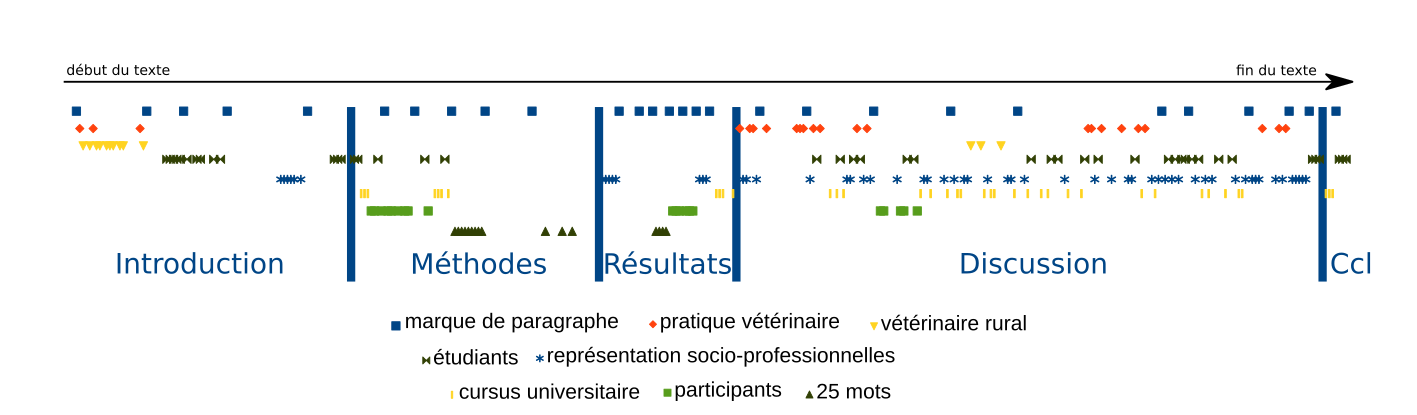
Distribution de certaines mentions dans les sections IMRaD de l'un des textes
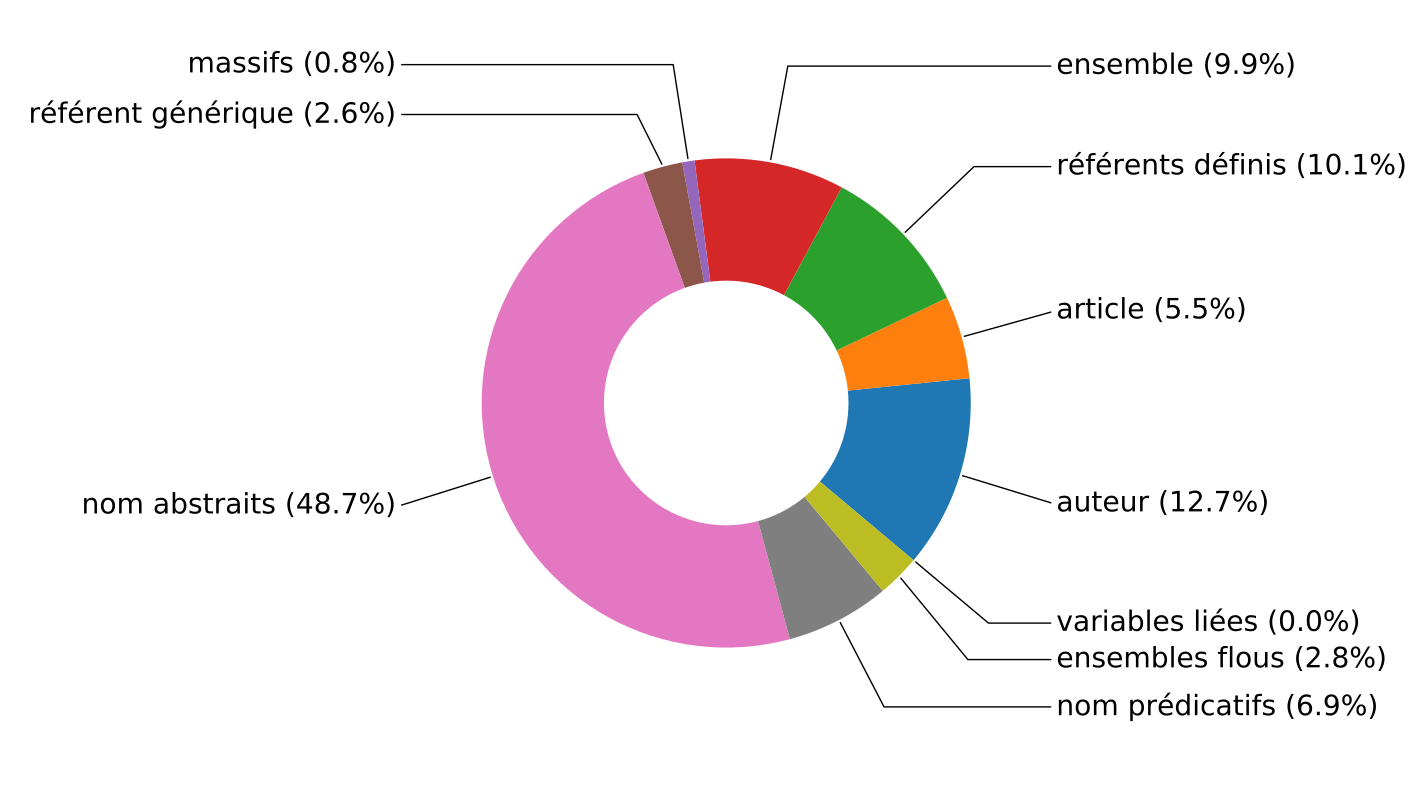
Exemple (extrait de l'article): Répartition des mentions de la section Introduction par types de référents
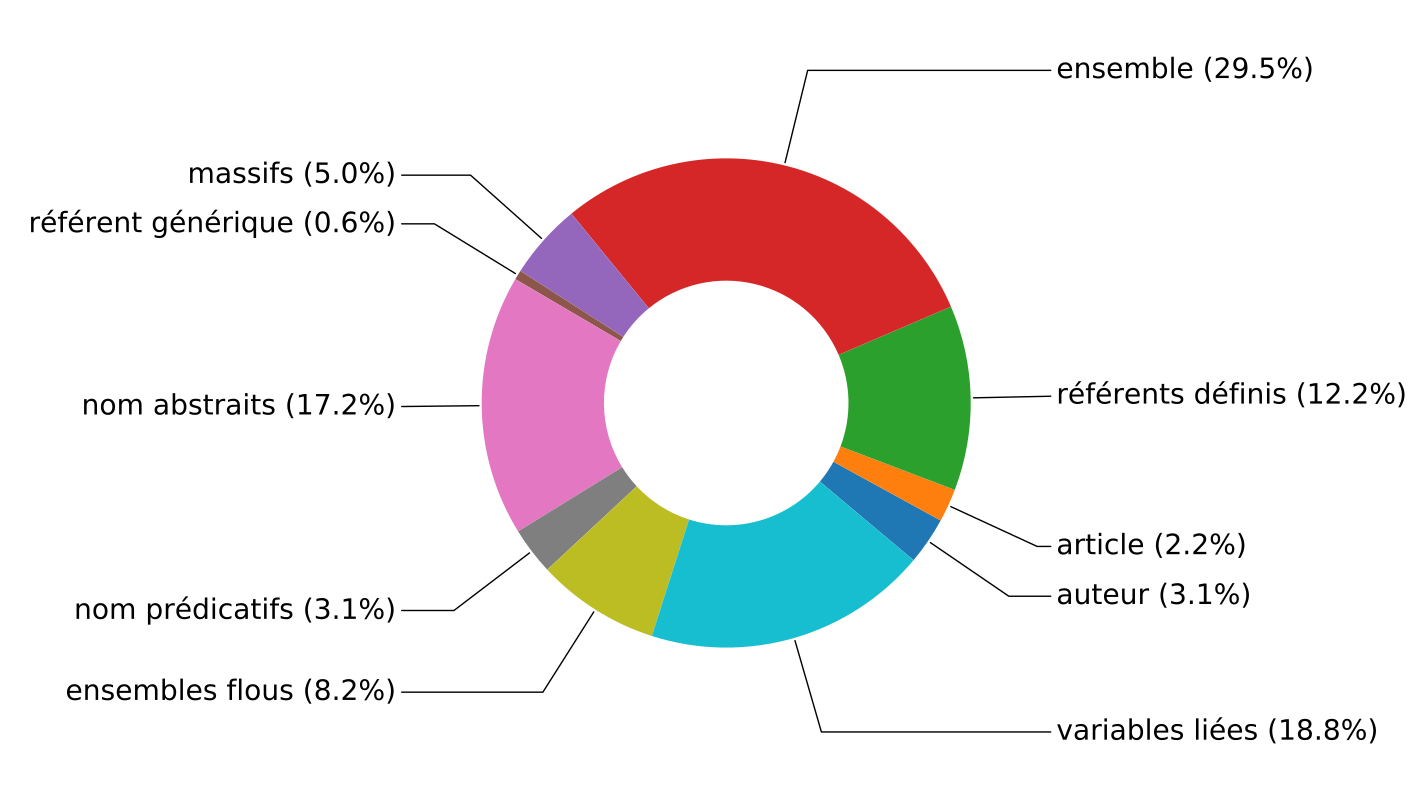
Exemple (extrait de l'article): Répartition des mentions de la section Méthodologie par types de référents
Pour voir l'autre mémoire: ODACR: un Outil de Détection Automatique des Chaînes de Référence à base de règles linguistiques.