A rule-based coreference resolution tool (master thesis)
I have two French master degrees:
- one in language technologies (Technologies des langues),
- and one in French linguistics (Sciences du langage).
I have thus written two master theses. This page summarizes the first one: a rule-based automatic coreference resolution tool. For the other one (a linguistic study of coreference chain in IMRaD research articles), read here.
The thesis is entitled ODACR: un Outil de Détection Automatique des Chaînes de Référence à base de règles linguistiques (a rule-based automatic coreference resolution tool). I have created two resources: a dictionary of entities for coreference detection from Wikipedia and WordNet and a dictionary of hypernyms.
Part of if has been publish in a scientific paper: Détection automatique de chaînes de coréférence pour le français écrit: règles et ressources adaptées au repérage de phénomènes linguistiques spécifiques. Actes des Rencontres des Etudiants Chercheurs en Informatique pour le Traitement Automatique des Langues (TALN-RECITAL), Association française pour l'Intelligence Artificielle, Toulouse, Juillet 2019.
read the thesis (135 pages) read the paper read the poster
Both theses are related to coreference chains. A coreference chain is the set of all expressions of a text that refer to the same referent (referring expressions). For example, all the expressions in bold in the following text refer to the same entity "Sophia Loren":
[Sophia Loren] says [she] will always be grateful to Bono. [The actress] revealed that the U2 singer helped [her] calm down when [she] became scared by a thunderstorm while travelling on a plane. (This example is from Mitkov's Anaphora Resolution book.)
There is a second chain for the entity "Bono".
Each expression that is part of a coreference chain is called a mention.
I developed a new rule-based coreference resolution system for written French. This system takes into account linguistic phenomena often ignored by other (more machine learning oriented) systems. For example:
- full NP coreference resolution (noun-noun relations as opposed to noun-pronoun relations) (I built two lexical resources for this, see below):
- when two common nouns are involved (as in My cat... This animal),
- when two proper nouns (named entities) are involved (as in New York... The Big Apple),
- when a proper noun and a common noun are involved (as in The Seine... This river);
- groups (or lists), as in Peter, Paul and Jack (this is done with an analysis of the syntactic tree of the sentence),
- null anaphora, as in Peter drinks and ø smoke (this is also done by looking at the syntactic tree),
- first and second person pronouns in quotations as in Paul said: “I like chocolate” (this is done by looking at quotation marks and verbs meaning “say”),
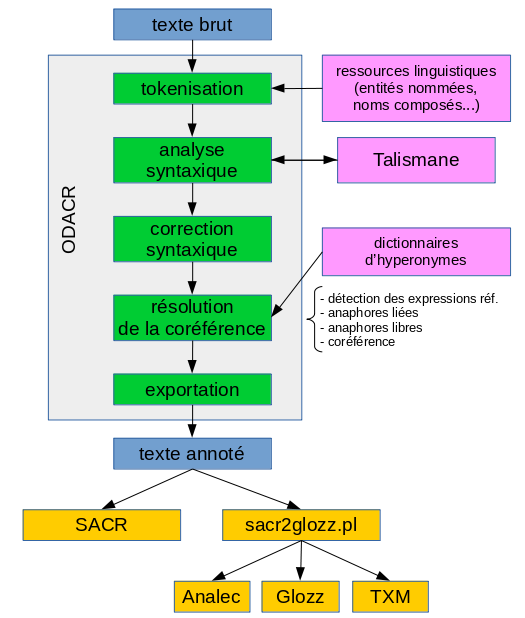
The two lexical resources for French I have built are:
First, a dictionary of named entities and proper nouns from Wikipedia and WordNet, based on Yago (chapter 4.1 of the thesis). For each entity, it records:
- the type of the entity (person, organization, location, etc.)
- how the entity may be designated (New York City... The Big Apple...)
- what are the hypernyms (TODO: wordnet_football_player_110101634)
- the gender: feminine or masculine, to be able to define the gender of the pronoun that would be used to refer to the entity (for instance, “Marie Curie” would be referred to as “she” but “Pierre Curie” as “he”).

Second, dictionary of common noun hypernyms, from the Wiktionary (XMLfied by Glawi) (chapter 4.2 of the thesis). Entry definitions usually start with an hypernym. For example:
- cat: An animal of the family Felidae,
- table: Furniture with a top surface to accommodate a variety of uses.
- apple: A common, round fruit produced by the tree Malus domestica...,
So I have collected these hypernyms and have turned them into a dictionary, for instance: chat > mammifère > animal > métazoaire.
I also crafted rules to correct the tree given the syntactic parser I used (Talismane) (chapter 5 of the thesis). This was done after a careful error analysis. For example (click to enlarge):


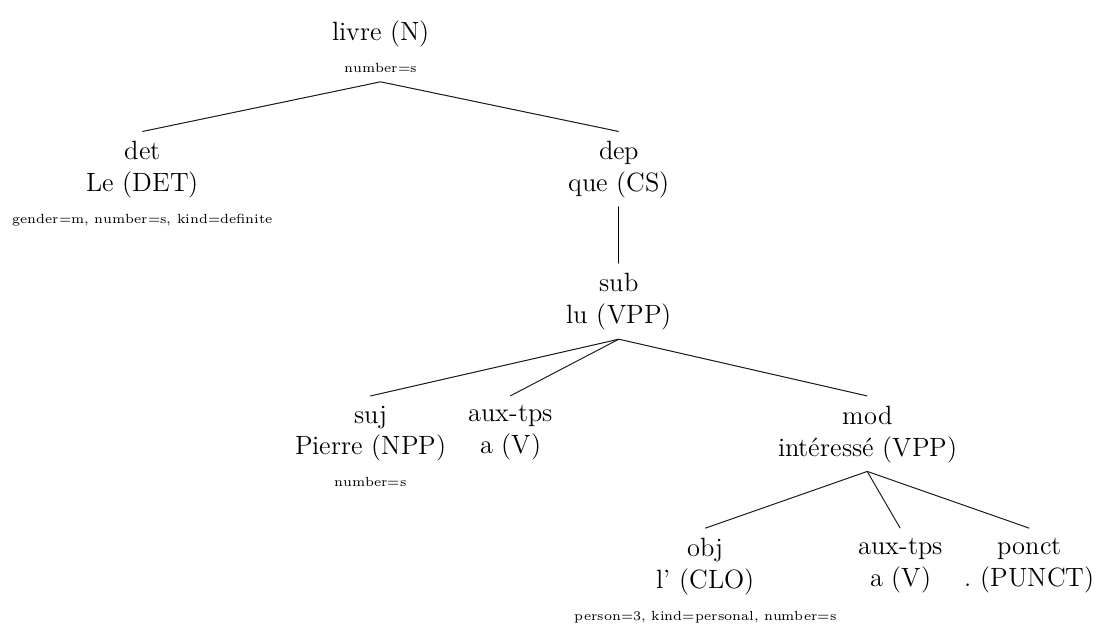
original (output from Talismane)
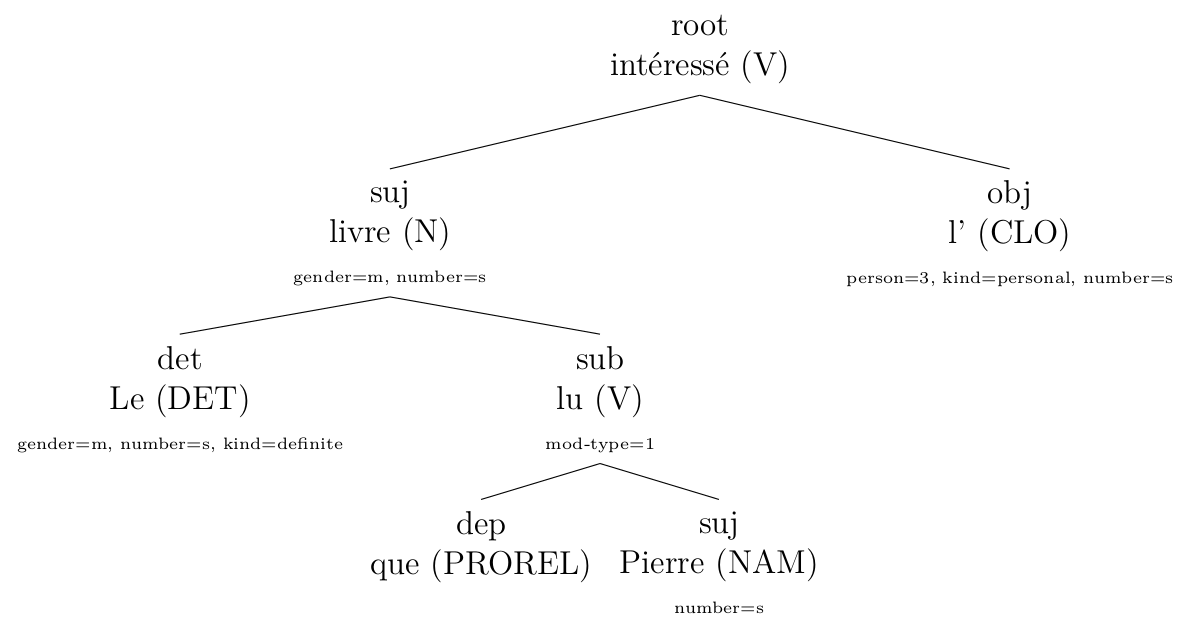
corrected with my rules
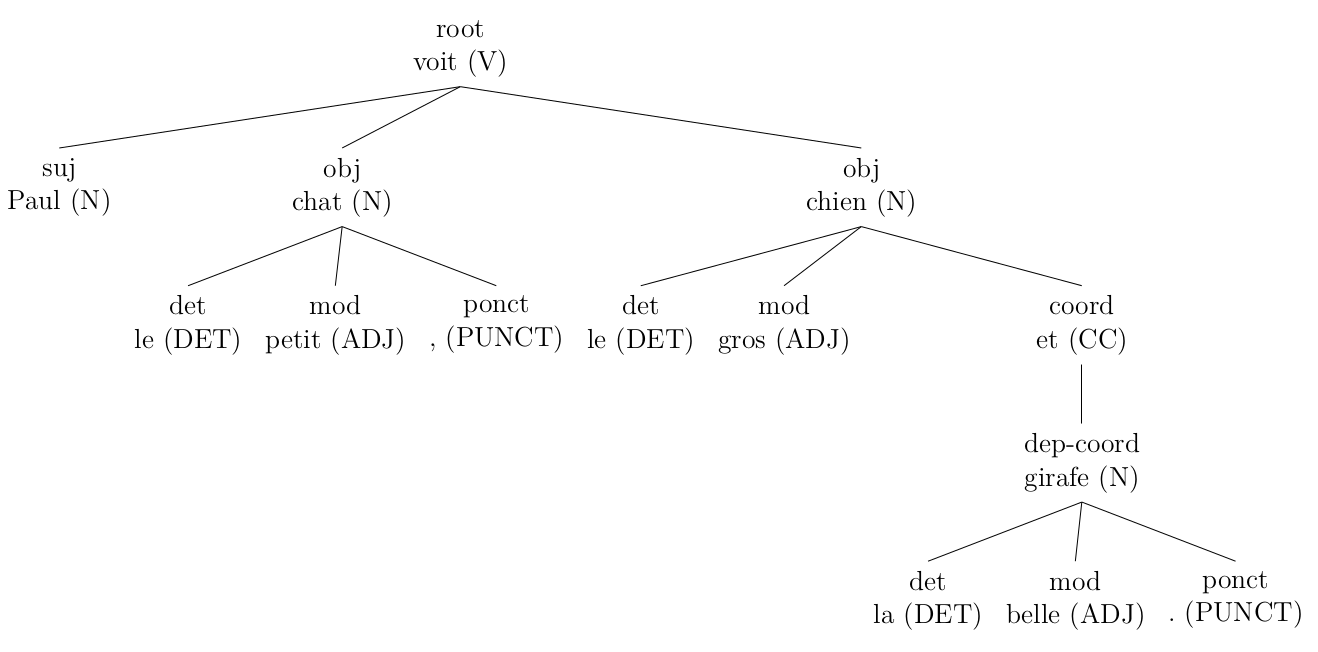
Other rules are used to simplify the tree, for example to unite different items of a same group (click to enlarge):
original (output from Talismane)
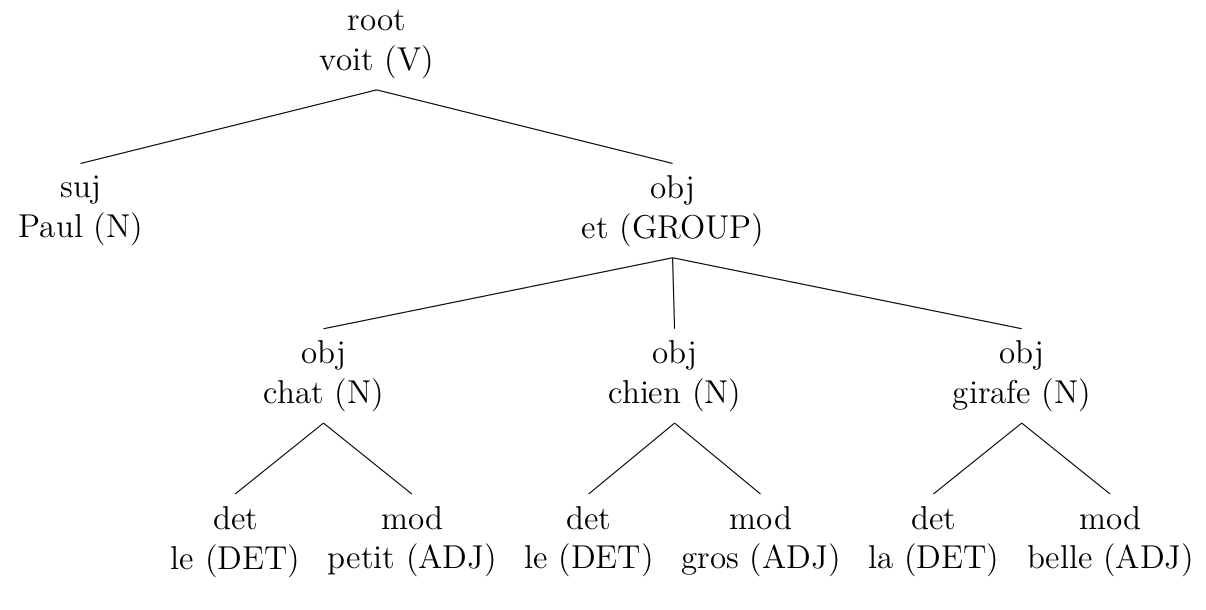
corrected with my rules
Or to divide coordinated (click to enlarge):
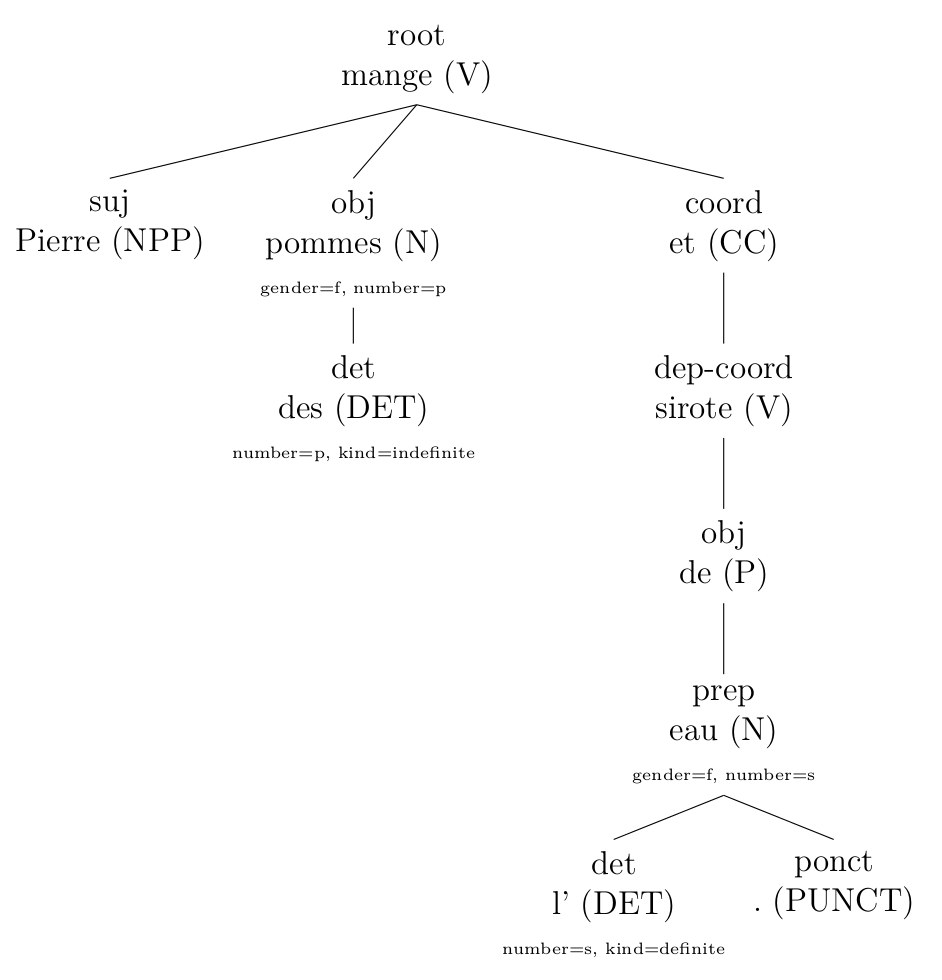
original (output from Talismane)
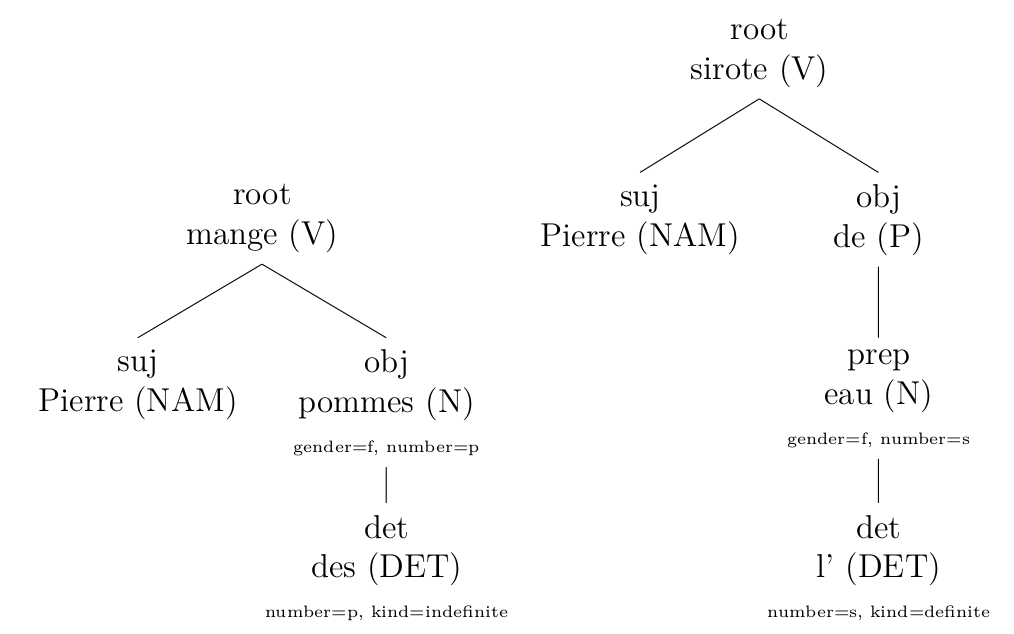
corrected with my rules
The coreference resolution algorithme in itself has several passes:
- first, it deals with anaphora cases for which only syntactic information is required to find the antecedent, such as reflexive pronouns (the antecent is the subject of the clause), relative pronouns (the noun modified by the relative clause), pronouns of the type myself, I, etc.,
- then other anaphora cases (such as personal pronouns), for which finding the antecedent required syntactic information but also other information such as gender, number, if the expression is in a quotation, etc.,
- coreference of named entities, with the help of the named entity and proper name dictionary,
- coreference of other nouns, with the help of the hypernym dictionary and saliency information.
read the full thesis (in French)
To see the other master thesis: Ccoreference chains in IMRaD research articles.