Projects
I enjoy creating open-source tools that are useful to me (and hopefully others too).
Data labelling, NLP, conversions between formats... but also scraping, playing media, mobile application, Firefox extension... all the way to Ancient Greek grammar.
The techs I use are Python, JavaScript, Go, C, React Native...
Other projects are on Github .
Coreference Annotation Tool (SACR)
A tool for annotating mentions and coreference relations using a simple drag-and-drop interface.
Optimized for ease of annotation, it provides a visual representation of relations, numerous shortcuts, and search options.
Supports feature annotation for each mention, such as part of speech, grammatical gender, number, etc. The annotation set is fully customizable.
Allows conversion of annotations to and from various formats, including CoNLL and TXM.
A single-page application developed in Vanilla JavaScript.

Automatic Coreference Resolution for Spoken and Written French With AI (cofr)
A coreference resolution model trained on the Ancor and Democrat corpora.
The model detects mentions, including singletons, as well as coreference relations.
The model is the result of fine-tuning BERT, one of the first large language models (LLMs). TensorFlow was used.
This work was published in LREC 2020.

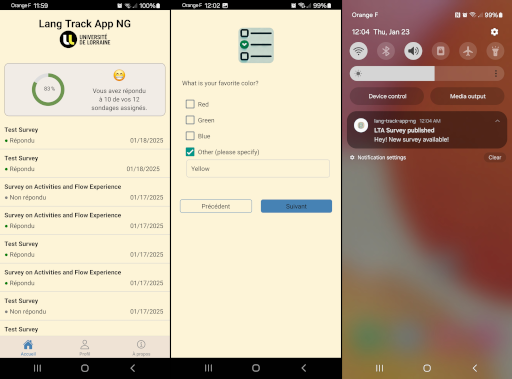
Lang Track App (Next Generation): A survey app
A project designed to enable a research team to send small but frequent surveys to participants via a mobile app and a website.
It includes a mobile app for Android and iOS, a back-office system, and a backend.
Reminders are sent via push notifications, emails, and/or SMS.
Developed using Python, React, and React Native.
Currently in the testing phase.
Conversion scripts for various coreference annotation formats (corefconversion)
A collection of scripts and tools for converting between various formats used in coreference annotation.
Supported formats include CoNLL, Brat, JSONLines, Glozz, SACR, plain text, and more.
Most scripts are written in Python, with some in Perl.
Part of the script is available as a PyPI package (pip).

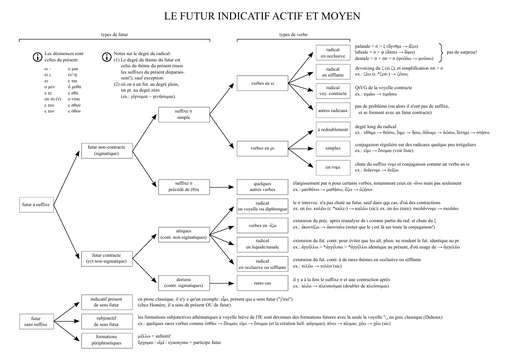
Ancient Greek linguistics and grammar reference sheets
A set of 150 reference sheets (approximately 420 pages) providing an analytical description of the morphology, tenses, moods, phonetics, and syntax of Ancient Greek.
They explain the different cases in great detail, with the help of diagrams.
I wrote them while studying Ancient Greek at the University of Strasbourg.
My goal was to be highly analytical in order to truly understand the underlying principles. Rather than simply memorizing declensions, these sheets help you grasp why the endings are what they are.
Vinted Downloader (Firefox Extension)
A simple Firefox add-on for downloading data and full-size photos from the Vinted app.
Allows downloading product data in JSON and text formats, as well as full-size photos.
Also supports downloading conversation data, including content, full-size images, and shipping (tracking) information.
Vinted Downloader (Python package)
A Python script for downloading data and full-size photos.
Downloads product data in JSON and text formats, along with full-size photos.
Supports downloading conversations, including content, full-size images, and shipping (tracking) data.
Available on PyPI (pip) and can be invoked using the command vinted-downloader.
Coreference databases and corpora for English and French (corefdb)
A database containing coreference data (mentions, chains, and relations) and textual structures (tokens, sentences, paragraphs, and texts), enriched with linguistic annotations (e.g., part of speech, named entities, etc.).
This is an enhanced version of the Democrat corpus for French.
Python scripts are available to create custom databases from other corpora (e.g., CoNLL or user-provided annotations).
Coreference Analysis Tool (CRViewer)
A tool for computing coreference statistics and visualizing them using pie charts and bar plots.
The tool is written in Java and processes input files annotated with SACR.
It supports other annotation formats (e.g., CoNLL) with conversion.
Random item generator
A website for quickly generating random items such as names, emails, cities, HTML text, pictures, locations with maps, user profiles, and more.
You can generate simple lists or more complex structures with loops and groups.
All data is sourced from Wikipedia and has been randomized.
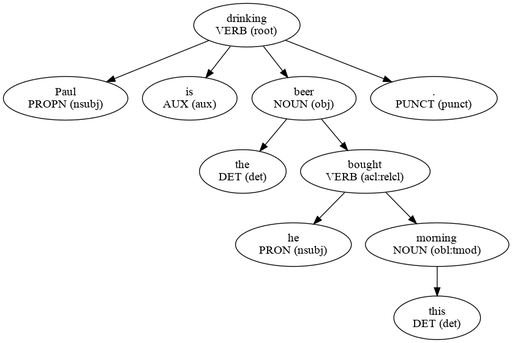
Tree Visualization of a Dependency Parser (dependency2tree)
This tool converts the CoNLL output from dependency parsers, such as StanfordNLP (for English) or Talismane (for French), into LaTeX or Graphviz tree representations.
Rephraise: Using IA to reformulate a text
A tool for rephrasing text, with options to adjust formality and maintain varying levels of similarity to the original.
The best part is that you can instantly see the differences, similar to a GitHub or GitLab diff.
I use it to refine my support emails to customers. 😅
It simply sends data to the OpenAI API.
Available in French and English.
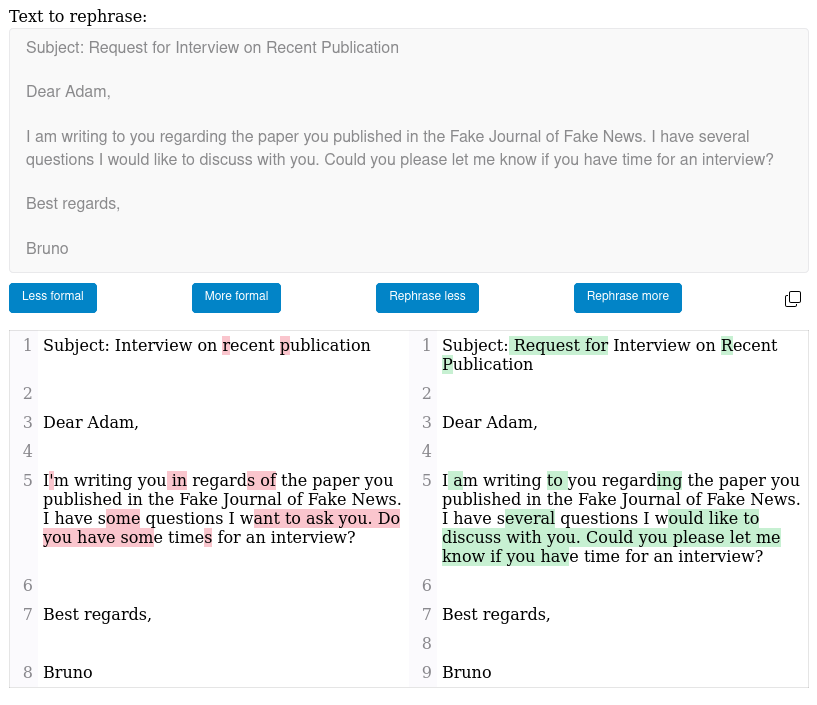
Visual Representation of Coreference Relations
Various ways for representing coreference relations between linguistic expressions in a text.
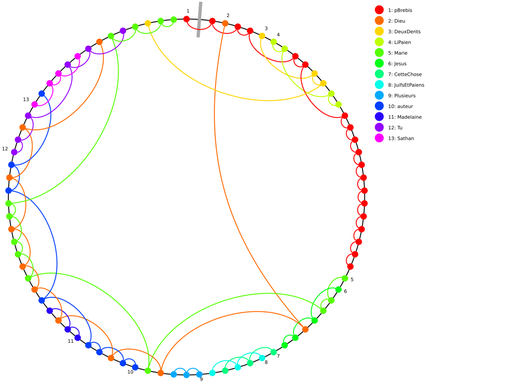
NASA and USGS raw Elevation Models as images (hgt2pnm)
This Python script converts raw elevation models from NASA and USGS into a PNM image.
HGT files contain elevation data provided by USGS and NASA. Each pixel represents either 1 or 3 meters, depending on the region.
The data is provided as a 16-bit signed integer in Motorola byte order.
This tool converts the data into a standard Linux byte order and outputs an image.
Draw a Frame on your Screen (drawframe)
A program that draws a frame appearing above all other windows, useful for recording screencasts.
This tool is written in C and designed for Linux systems using X11.

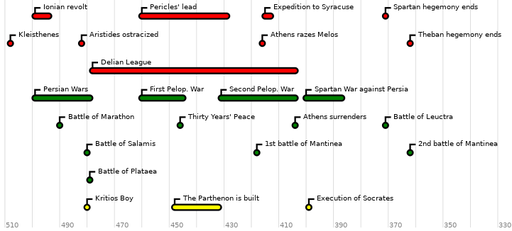
Visual Timeline Creator (mktimeline)
A tool for creating visual timelines from a list of dates and event names.
This lightweight tool is written in Perl 5.
Ancient Greek Font
An Ancient Greek font, created with FontForge, that resembles the one used by a famous French publisher.

Laboratory DC Power Generator
How I built a laboratory DC power generator (2 × 1.2V to 20V, 333mA).
