Tree visualization of a dependency parser (dependency2tree)
Convert CoNLL output of a dependency parser into a latex or graphviz trees:

download code view github repo
Introduction
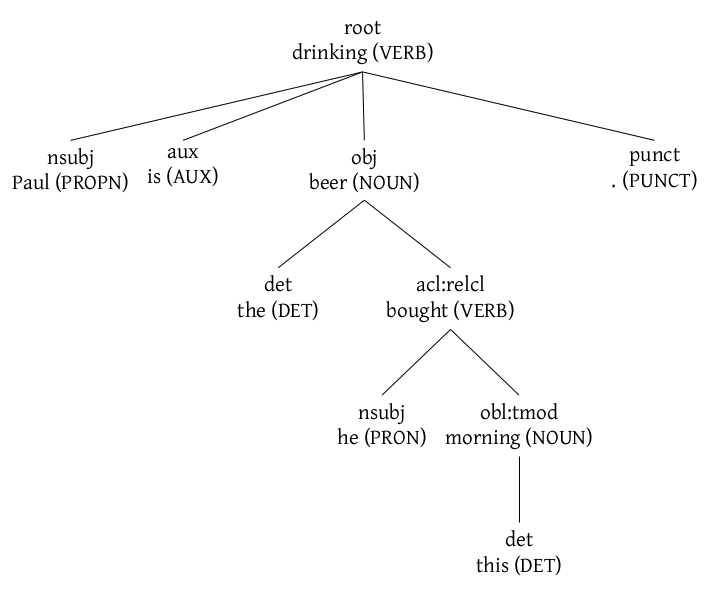
For example, here is a sample output form the the StanfordNLP from which the previous images have been made (using Latex and GraphViz modes, respectively):
1 Paul Paul PROPN NNP Number=Sing 3 nsubj _ _
2 is be AUX VBZ Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin 3 aux _ _
3 drinking drink VERB VBG Tense=Pres|VerbForm=Part 0 root _ _
4 the the DET DT Definite=Def|PronType=Art 5 det _ _
5 beer beer NOUN NN Number=Sing 3 obj _ _
6 he he PRON PRP Case=Nom|Gender=Masc|Number=Sing|Person=3|PronType=Prs 7 nsubj _ _
7 bought buy VERB VBD Mood=Ind|Tense=Past|VerbForm=Fin 5 acl:relcl _ _
8 this this DET DT Number=Sing|PronType=Dem 9 det _ _
9 morning morning NOUN NN Number=Sing 7 obl:tmod _ _
10 . . PUNCT . _ 3 punct _ _
And here are the trees using the Latex mode and the GraphViz mode:
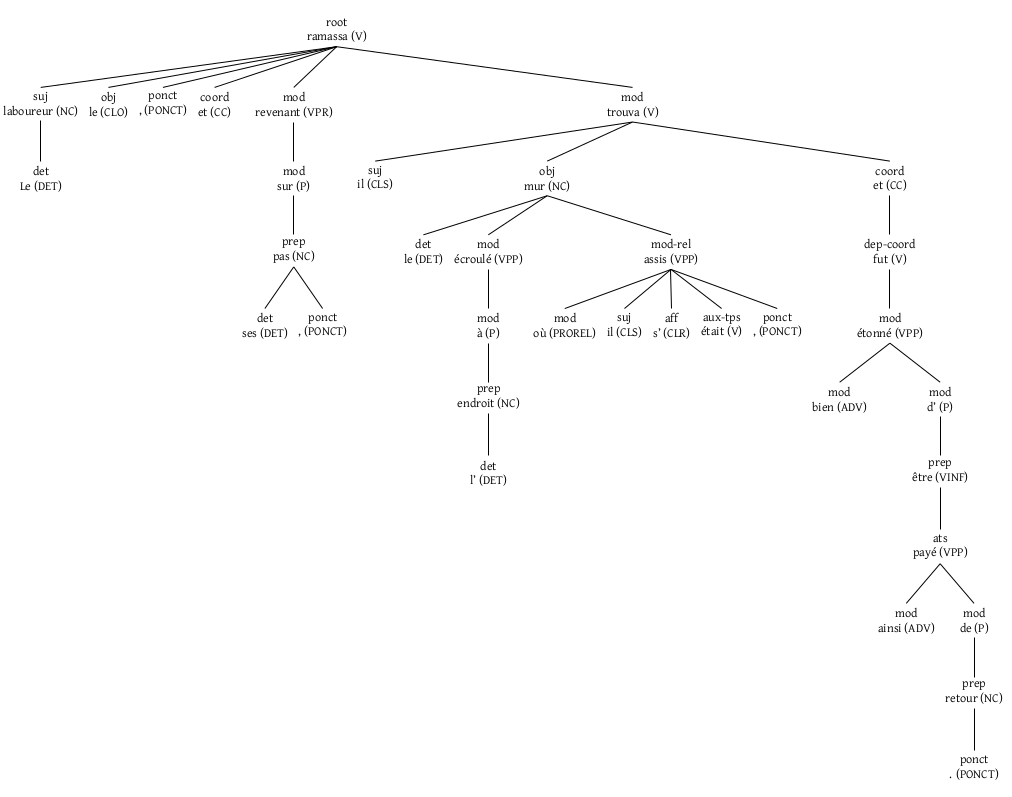
Examples of big trees in French (using outputs from Talismane):

Dependency parsers that uses the CoNLL parser includes:
- StanfordNLP (for multiple languages)
- CoreNLP (for multiple languages)
- Talismane (for French)
- MindTheGap (for French)
- ...
Quick start
There are two modes: Latex or Graphviz. With the Latex mode, all the sentences will be in a file, each on its own page. The script produces a .tex file, named according to the -o option, which is compiled if the -c switch is set (otherwise, just run pdflatex|lualatex <file>.tex). To activate this mode, you must use the the -l swith or the -m latex option:
For example:
or
This will produces a output.pdf file containing your trees. Of course, you will need to install pdflatex or lualatex (with your package manager of with texlive).
In the GraphViz mode (the default mode), each sentence is in its own file. If you don't want to compile, you can get graphviz files with:
You will get output-001.gv, output-002.gv, etc. for each sentence. You can run dot to get image files (replace svg by the format you want):
The dot command comes with the graphviz program, which can be installed on Ubuntu with the following command:
If you want to compile automatically with the -c switch, just adjust the output file extension to svg (or png, etc.) instead of gv:
This will get you output-001.svg, output-002.svg, etc. You can change the image format (png, etc.) with -f option:
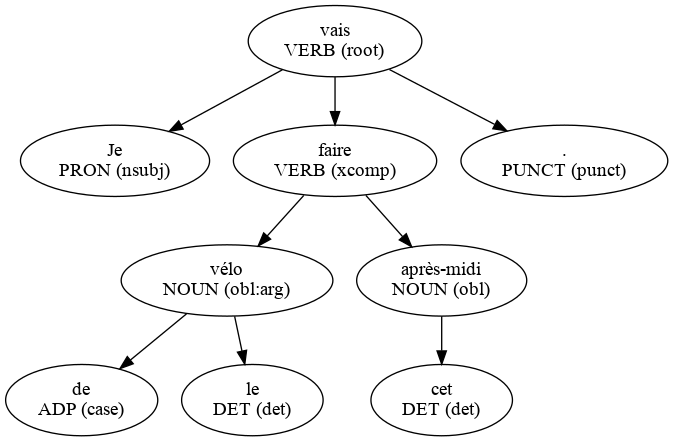
Some corpora (as GSD) decompose French amalgams (for example "du" is decomposed to "de le"). The original word is saved within the conll file with a hyphen in the index:
1 Je il PRON ...
2 vais aller VERB ...
3 faire faire VERB ...
4-5 du _ ...
4 de de ADP ...
5 le le DET ...
6 vélo vélo NOUN ...
7 cet ce DET ...
8 après-midi après-midi NOUN ...
9 . . PUNCT ...
Use the --ignore-double-indices option to ignore these words:
For more information, run: