Coreference databases and corpora for English and French (corefdb)
Analyse coreference in a corpus with a relational databases containing tables for coreference data (mentions, chains, relations) as well as for textual structures (tokens, sentences, paragraphs, texts). Includes linguistic annotations (part of speech, named entity, etc.).
Enriched version of the Democrat corpus for French.
In this presentation document, you will find:
- an introduction,
- a list of corpora (CoNLL, Democrat, Ancor) and how I have added annotation layers to the Democrat corpus (the same annotation layers have been added to Ancor),
- the representation of the corpora and all their linguistic annotations as a relational databases, with a complete list of all the fields for each table, and the possible values,
- the other formats (conll, jsonlines) the corpora are available in,
- the availability of the corpora and their licenses with all the legal stuff from the original corpora,
- instructions on how to compile the database (for CoNLL, Democrat, Ancor or for you own text or corpus).
- the license for the scripts, and how to cite the modified corpora if you use them.
download code view github repo
On this page:
Introduction
Coreference is the relation between two expressions of a text that refer to the same world entity. When there are several such expressions, they form a coreference chain. For example, all the expressions in bold in the following text refer to the same entity Sophia Loren:
[Sophia Loren] says [she] will always be grateful to Bono. The actress revealed that the U2 singer helped [her] calm down when [she] became scared by a thunderstorm while travelling on a plane. (This example is from Mitkov's Anaphora Resolution (2002).)
Notice that there is a second chain for the entity Bono.
Each expression that is part of a coreference chain is called a mention.
Corpora
Available corpora
They are several corpora with coreference annotation in English as well as in French. The most known corpus in English is the CoNLL-2012 corpus (1.6m tokens, from the OntoNotes corpus), which was used to evaluate systems presented in the CoNLL-2012 shared task (a competition in which several automatic coreference resolution systems competed). This corpus, based on the OntoNotes corpus, offer several annotation layers, with parts of speech, lemmas, segmentation into phrases and clauses (constitency syntactic parses), named entities, argument structures, reference to WordNet, alongside coreference.
In French, the Ancor corpus (460k tokens) is a corpus of transcribed oral French, with some part of speech and named entity annotation. Because it is based on conversations and interviews, it contains specific features of oral language, such as disfluencies (word repetitions, interjections as euh "er") and no punctation nor sentence boundaries.
The Democrat corpus (689k tokens for the whole corpus, 285k for modern texts), on the other hand, is a multi-genre corpus of written texts, from the 12th to the 21st century. But, besides coreference, it has no valid linguistic annotation whatsoever. In this repository I offer an enriched version the Democrat corpus, in various formats (including a relational database, as well as CoNLL, jsonlines and text formats), used in the following paper:
to train both ODACR and COFR and described in the LREC paper. Note that ODACR was originally from:
Oberle Bruno, Détection automatique de chaînes de coréférence pour le français écrit: règles et ressources adaptées au repérage de phénomènes linguistiques spécifiques. TALN-RECITAL 2019
Annotation layers added to Democrat (19th to 21st-century texts)
Most of the texts from the Democrat corpus are narratives, usually 10k word-long extracts from novels, short stories and biographies. But there are also Wikipedia articles and 103 press articles. These texts are concatenated into one document in the original distribution: I have separated them using their "natural boundaries" (that is, the beginning and the end of the text). For the modern part of the Democrat corpus, I have kept only texts from the 19th to the 21st centuries, hence the name of the subcorpus: "Dem1921". Five documents are excerpts from legal texts; I have excluded them since they are written in a specialized legal language.
So the main part of Dem1921 focuses on 126 modern documents; 103 are small but complete press articles from the newspaper L'Est Républicain and 23 of them are 10k word-long excerpts from mostly narrative texts. Note that a technical issue has occurred when concatenating the three Wikipedia texts in the original corpus. Here, I have used the correct version of these texts.
The Democrat corpus is provided in an xml format compliant with TEI. I have converted it to the conll format (tabulation separated text file, one token per line), with a supplementary column for paragraph information. I have also manually harmonized the typography (e.g. the type of apostrophe or quotation marks).
The original version of Democrat only contains parts of speech from TreeTagger. Sentences are split at every full-stop; some mentions are thus split across several sentences, e.g. the name J. B. L. Bard is split across four sentences. For this reason I have decided not to keep the original tokenization and sentence splitting.
First, I used the StanfordNLP dependency parser to perform tokenization and sentence splitting, and to add syntactic parses. After an error anlysis of the tokenization and sentence splitting, I have adjusted parameters and input data to get the best possible results. I have also corrected systematic errors, mostly to ensure that no mention is split across several sentences. The tagsets used for parts of speech and dependency labels are the Universal Dependencies tagsets.
Lemmatization has been done by a lookup in a morphological and syntactic lexicon (Lefff).
I have added named entities with the Flair tool. Four types are defined: persons (PER), locations (LOC), organizations (ORG) and a miscellaneous (MISC) category (usually when the tool was unable to categorize a detected entity into one of the three previous categories). After a error analysis, I kept all the PER, LOC and ORG. From the MISC entities, only those with a probability higher then 0.8 have been kept, and for those, I have corrected the list manually. For the MISC entities the text of which was found elsewhere in the text with a different type, I subsituted the MISC type by the other type. For example, if "Peter" was here PER and there MISC, I gave it the category PER everywhere.
The output format is CoNLL-U, with supplementary columns for named entities, paragraph number, and, of course, coreference chain.
Note that the original layers for CoNLL and the layers I have added for Democrat are not the same (besides the language difference): CoNLL has constituency parses whereas Democrat has dependency parses; CoNLL has 18 named entity types whereas Democrat has only four...
For Ancor, a parallel work has been done by Rodrigo Wilkens, with the same tools, from the raw text.
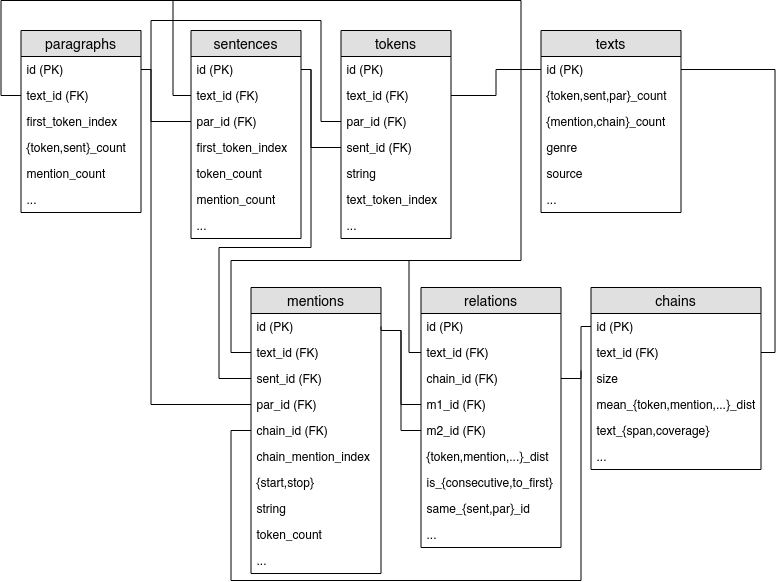
Databases
The three corpora, CoNLL-2012, Democrat and Ancor, are here mainly presented as a relational database containing table for textual structures:
- tokens,
- sentences,
- paragraphs,
- texts;
and for coreference annotation:
- mentions (referring expression),
- coreference chains,
- relations between consecutive mentions in a same chain.
All these tables are related according to the following diagram:
The list of fields is detailed in the next section.
Complete list of fields in the database
This section presents all the fields in the relational database. Since CoNLL and Democrat/Ancor do not have the same annotation layers (for example, CoNLL uses constituency parses while the syntactic information added to Democrat/Ancor are dependency parses), there are some differences between the corpora of the two languages. A UK flag ( ) indicates a feature present in the CoNLL corpus, while a France flag (
) indicates a feature present in the CoNLL corpus, while a France flag ( ) indicates a feature present in Democrat and Ancor.
) indicates a feature present in Democrat and Ancor.
There are three annotation complexity levels. The base level, indicated by a green disk ( ) can be computed for all texts and corpora: it only uses coreference annotation. You can use the available script (
) can be computed for all texts and corpora: it only uses coreference annotation. You can use the available script (db_builder.py, see below) to compute this level for your own text, without having to add any other linguistic annotations. The linguistic level (blue:  ) requires the files to have linguistic layers added: syntactic parses and named entities, as described above. The advanced level (purple:
) requires the files to have linguistic layers added: syntactic parses and named entities, as described above. The advanced level (purple:  ) doesn't required more annotations, but rather external resources: WordNet and FastText and the Pyton modules used to compute them (NLTK and Gensim), as well as some processing time.
) doesn't required more annotations, but rather external resources: WordNet and FastText and the Pyton modules used to compute them (NLTK and Gensim), as well as some processing time.
To save space, field names are sometimes indicated with a set notation: {a,b}_something must be understood as two fields: a_something and b_something. The term buckets indicates that values have been distributed accross a range of buckets (or bins): [00-01[, [01-02[, [02-04[, [04-08[, [08-16[, [16-32[, [33+.
Here are the links to jump directly to a specific table:
Table Chains
Primary and foreign keys:
| 1 | id | ||
| 1 | text_id |
Coverage of the chain in the text:
| 2 | size: number of mentions | ||
| 2 | text_span: number of tokens between the first and the last mention of the chain | ||
| 2 | text_coverage: text_span divided by the number of tokens in the text |
Rank of the mentions:
| 2 | mean_mention_level: level is the number of nested mentions (0 = outer mention, not nested) | ||
| 2 | {mean,median}_{sent,par,text}_mention_rank: the mention rank is the position of the mention in the chain: the first mention of the chain has the rank 0. The sentence mention rank is the position of the mention in the chain in a specific sentence. For example, the second mention of the chain has the rank 1, but if it is the first mention of the chain |
Distances between two consecutive mentions in the chain:
| 2 | {median,mean}_{token,mention,sent,par}_dist: mean distance between two consecutive mentions in number of tokens, mentions, sentences, paragraphs | ||
| 2 | distribution_of_{token,mention,sent,par}_dist_{buckets}: distribution in buckets of distances of consecutives mentions | ||
| 2 | distribution_of_mention_length_{buckets}: distribution in buckets of lengths of the mentions of the chain |
Shape of the distribution of the distances between two consecutive mentions in the chain (the distribution is virtually never normal):
| 2 | dist_{skewness,kurtosis} | ||
| 2 | lafon: Lafon’s burst coefficient (Lafon, Pierre (1984). xx.x.x..........xxx......xxxx you see that the x's are not evenly distributed, they form “bursts” |
Variation in the chain:
| 2 | pattern_diversity: number of tri-grams (of part of speech) of consecutive mentions divided by the number of mentions in the chain | ||
| 2 | stability_coeff_string: stability coefficient (a number between 0 and 1: if 0, all the nouns in the chain are different (ex.: the cat… the animal), if 1 all the nouns in the chain are the same (ex.: the cat… the cat…), if between there are some repetition and some difference | ||
| 2 | stability_coeff_h_lemma: same as before but only noun lemma are considered (and not the whole mention string) |
Named entity type of the chain (for chain that have at least one mention that is a named entity):
| 2 | type |
Proportions:
| 2 | outer_proportion: an outer mention is a mention that is not nested | ||
| 2 | proportion_of_named_entities | ||
| 2 | has_multiple_speakers | ||
| 2 | proportion_of_subjects | ||
| 2 | proportion_of_mentions_in_pp | ||
| 2 | proportion_of_mentions_in_main_clause | ||
| 2 | mean_node_depth: depth of the syntactic head in the syntactic tree | ||
| 2 | proportion_of_mention_with_dependents: proportion of mention with at least one dependent | ||
| 2 | proportion_of_{n,p,d,v,o}: proportion of noun, pronoun, determiner ( | ||
| 2 | proportion_of_proper_nouns | ||
| 2 | is_plural: the chain has at least one mention that is tagged as plural | ||
| 2 | proportion_of_first_arguments: proportion of mentions that are the first argument in their argument structure |
The following fields are copied from the texts table for convenience:
| 2 | text_genre | ||
| 2 | text_source | ||
| 2 | text_token_count | ||
| 2 | text_mention_count | ||
| 2 | text_chain_count |
Table Mentions
Primary and foreign keys:
| 1 | id | ||
| 1 | chain_id | ||
| 1 | par_id | ||
| 1 | sent_id | ||
| 1 | text_id |
Positions:
| 1 | {start,end}: index of the first and last tokens of the mention in the sentence | ||
| 1 | par_{start,end}: index of the first and last tokens of the mention in the paragraph | ||
| 1 | text_{start,end}: index of the first and last tokens of the mention in the text | ||
| 1 | chain_mention_{index,rindex}: index of the mention in the chain (first mention has index 0), from the start/from the end | ||
| 1 | {sent,par}_mention_index: index of the mention in the sentence/paragraph | ||
| 1 | par_sent_index: index of the sentence (in which the mention is) in the paragraph (first sentence of the paragraph has index 0) | ||
| 1 | text_mention_index: index of the mention in the text (first mention of the text has index 0) | ||
| 1 | text_par_index: index of the paragraph (in which the mention is) in the text (first paragraph of the text has index 0) | ||
| 1 | text_sent_index: index of the sentence (in which the mention is) in the text (first sentence of the text has index 0) | ||
| 1 | {sent,par,text}_mention_rank: the mention rank is the position of the mention in the chain: the first mention of the chain has the rank 0. The sentence mention rank is the position of the mention in the chain in a specific sentence. For example, the second mention of the chain has the rank 1, but if it is the first mention of the chain in the sentence (that is, the first mention of the chain is in a different sentence), its sentence rank will be 0 |
Content:
| 1 | string: the textual content of the mention | ||
| 2 | token_count: the number of tokens |
Nestedness:
| 1 | is_outer: an outer mention is a mention that is not nested | ||
| 1 | parent: id of the direct parent, that is the mention in the which the current mention is nested into (for nested mention) | ||
| 1 | level: the level of nestedness (the outer mention has a level of 0) |
Dominant node in the syntactic tree:
| 1 | node_id: head node id (this id is not referenced elsewhere in the database, it is an arbitrary number used only for the two next fields) | ||
| 1 | parent_node_id: parent node of the head node | ||
| 1 | grandparent_node_id: grand parent node of the head node |
Named entity:
| 1 | named_entity_type: types vary according to the corpora (18 types for CoNLL, 4 types for Democrat/Ancor, see the complete list of values) | ||
| 1 | is_named_entity: whether the mention is a named entity | ||
| 1 | is_name: whether the mention is a named entity is of one of the types PERSON, FACILITY, ORG, GPE, WORK OF ART, NORP, LOCATION, PRODUCT, EVENT, LAW, LANGUAGE | ||
| 1 | is_pers: whether the mention is a named entity is of one of the type PER |
Speaker:
| 1 | speaker: for CoNLL and Ancor (dummy value for Democrat) |
Type of the mention:
| 1 | is_clause | ||
| 1 | is_phrase | ||
| 1 | is_word |
Morphosyntax:
| 1 | tag | ||
| 1 | pspeech: alias for tag | ||
| 1 | pos | ||
| 1 | deplabel | ||
| 1 | subdeplabel |
Categories (according to UD):
| 1 | is_relative_pronoun | ||
| 1 | is_reciprocal | ||
| 1 | is_reflexive | ||
| 1 | is_expletive | ||
| 1 | is_complement | ||
| 1 | is_apposition | ||
| 1 | is_verb | ||
| 1 | is_verb_without_subject |
Morphosyntax and syntax of the parent:
| 1 | parent_phrase_tag | ||
| 1 | parent_pos | ||
| 1 | parent_deplabel | ||
| 1 | parent_subdeplabel | ||
| 1 | parent_clause_tag | ||
| 1 | parent_clause_pos | ||
| 1 | parent_clause_deplabel | ||
| 1 | parent_clause_subdeplabel | ||
| 1 | parent_phrase_id | ||
| 1 | parent_clause_id |
Function:
| 1 | is_subject | ||
| 1 | is_object | ||
| 1 | is_non_core: neither subject nor object |
Preposition:
| 1 | in_pp: whether the mention is in a prepositional phrase | ||
| 1 | preposition: the text of the preposition |
Syntactic depth of the head node (for Democrat/Ancor) or of the constituent (for CoNLL):
| 1 | node_depth | ||
| 1 | clause_depth | ||
| 1 | phrase_depth |
Type of clauses:
| 1 | is_in_main_clause | ||
| 1 | is_in_matrix | ||
| 1 | is_embedded | ||
| 1 | is_in_embedded |
Dependents:
| 1 | dependent_count | ||
| 1 | predependent_count | ||
| 1 | postdependent_count | ||
| 1 | adjective_dependent_counter | ||
| 1 | noun_dependent_counter | ||
| 1 | clause_dependent_counter | ||
| 1 | phrase_dependent_counter | ||
| 1 | other_dependent_counter | ||
| 1 | num_dependent_counter | ||
| 1 | appos_dependent_counter | ||
| 1 | is_dependent | ||
| 1 | dependent_type |
Determiner:
| 1 | determiner_string | ||
| 1 | determiner_head_string | ||
| 1 | determiner_head_lemma | ||
| 1 | determiner_type | ||
| 1 | has_bare_determiner | ||
| 1 | has_genetive_determiner | ||
| 1 | has_complex_determiner | ||
| 1 | is_determiner | ||
| 1 | is_possessive | ||
| 1 | is_possessive_determiner | ||
| 1 | is_genitive | ||
| 1 | is_genitive_determiner |
Head:
| 1 | head: the actual text of the head | ||
| 1 | h_lemma: the lemma of the head |
Head position:
| 1 | h_{start,end}: index of the head in the sentence | ||
| 1 | h_text_{start,end}: in the text |
Morphosyntax and syntax of the head:
| 1 | h_pspeech | ||
| 1 | h_ud_pspeech | ||
| 1 | h_broad_pspeech: one of [npdvo] (noun, pronoun, determiner, verb, other) | ||
| 1 | h_noun_type: proper or common, see the possible values in the list of possible values | ||
| 1 | h_pronoun_type | ||
| 1 | h_reflex: is reflexive (if pronoun) | ||
| 1 | h_poss: is possessive (is pronoun) | ||
| 1 | h_definite: is definite (if determiner) |
Declension:
| 1 | h_number | ||
| 1 | h_gender | ||
| 1 | h_person |
Syntactic depth of the head:
| 1 | h_level | ||
| 1 | h_node_depth |
Argument structure:
| 1 | struct_id: the id of the structure; it is not referenced elsewhere in the relational database, it is an arbitrary number used to determine if two mentions are in the same structure | ||
| 1 | struct_is_negative | ||
| 1 | struct_is_passive | ||
| 1 | struct_tense | ||
| 1 | struct_mood | ||
| 1 | struct_person |
Arguments of the structure:
| 1 | is_arg: the mention matches the boundaries of an argument | ||
| 1 | arg_index: index of the argument in the structure (first argument has index 0) | ||
| 1 | arg_type: ARG0: agent; ARG1: patient; ARG2: instrument, benefactive, attribute; ARG3: starting point, benefactive, attribute; ARG4: ending point; ARGM: modifier, with a subclassification (LOC for locative, GOL for goal, etc.) | ||
| 1 | arg_is_agent: arg_type is ARG0 |
WordNet:
| 1 | wn: WordNet synset |
The following fields are copied from the texts table for convenience:
| 2 | text_genre | ||
| 2 | text_source | ||
| 2 | text_token_count | ||
| 2 | text_mention_count | ||
| 2 | text_chain_count |
The following fields are copied from the chains table for convenience:
| 2 | chain_size | ||
| 2 | chain_type | ||
| 2 | chain_coverage | ||
| 2 | chain_mean_token_dist | ||
| 2 | chain_median_token_dist |
Table Relations
Note that in the default databases, the relations are only relations between consecutive mentions.
Primary and foreign keys:
| 1 | id | ||
| 1 | chain_id | ||
| 1 | m1_id | ||
| 1 | m2_id | ||
| 1 | text_id |
Distance between the mentions in the relation:
| 2 | {token,mention,sent,par}_dist: in tokens, mentions, sentences, paragraphs |
Type of the relation:
| 2 | is_consecutive: the mentions of the relations are consecutive (always the case in the default database) | ||
| 2 | is_to_first: the first mention is the first mention of the chain (never the case in the default database) |
Comparing the two mentions:
| 2 | same_sent_id: are the mentions in the same sentence? | ||
| 2 | same_par_id: are the mentions in the same paragraph? | ||
| 2 | same_string: do the mentions have the same textual content? | ||
| 2 | same_is_outer: are the mentions both nested or both not nested? |
Part of speech type:
| 2 | type: a string composed of the h_broad_speech of the two mentions, for example n-n for two nouns, n-p for a noun and a pronoun, etc. |
Formal distance:
| 1 | levensthein | ||
| 1 | sorensen_dice |
Cosine similarity:
| 1 | context_similarity: (using FastText in English or French) |
WordNet distance (computed with NLTK, WOLF used for French):
| 1 | {min,max}_wup_similarity: when several synsets were possible for one or both mentions, all the combinations were computed: I report the min and the max value | ||
| 1 | {min,max}_path_similarity | ||
| 1 | {min,max}_shortest_path_distance | ||
| 1 | hypernymy: whether the mentions are in a hypernymic relationship | ||
| 1 | meronymy: whether the mentions are in a meronymic relationship |
The following fields are copied from the texts table for convenience:
| 2 | text_genre | ||
| 2 | text_source | ||
| 2 | text_token_count | ||
| 2 | text_mention_count | ||
| 2 | text_chain_count |
The following fields are copied from the chains table for convenience:
| 2 | chain_size | ||
| 2 | chain_type | ||
| 2 | chain_coverage | ||
| 2 | chain_mean_token_dist | ||
| 2 | chain_median_token_dist |
Table Tokens
Primary and foreign keys:
| 1 | id | ||
| 1 | par_id | ||
| 1 | sent_id | ||
| 1 | text_id |
Token features:
| 1 | text_token_index: position of the token in the text | ||
| 1 | string: the content of the token | ||
| 2 | pos: the part of speech |
Table Sentences
Primary and foreign keys:
| 1 | id | ||
| 1 | par_id | ||
| 1 | text_id |
Positions:
| 1 | {first,last}_token_index: index (in the text) of the first and last token of the sentence | ||
| 1 | par_sent_index: index of the sentence in the paragraph (first sentence has index 0) | ||
| 1 | text_sent_index: index of the sentence in the text (first sentence has index 0) | ||
| 1 | text_par_index: index of the paragraph (in which the sentence is) in the text (first paragraph has index 0) |
Table Paragraphs
Primary and foreign keys:
| 1 | id | ||
| 1 | text_id |
Positions:
| 1 | {first,last}_token_index: index (in the text) of the first and last token of the sentence | ||
| 1 | text_par_index: index of the paragraph in the text (first paragraph of the text has index 0) |
Table Texts
Primary and foreign keys:
| 1 | id |
Counts:
| 2 | {token,mention,chain,sent,par}_count |
Caracteristics of the text:
| 1 | genre: one of the predefined genres for CoNLL (nw, pt, etc.); for Democrat: wk, pr, ot (wikipedia, press, other); for Ancor, one of the subcorpus (ot, co, es, ub). | ||
| 1 | source: the source (for CoNLL: CNN, MSNBC, etc.) |
Mentions in the text:
| 2 | outer_proportion | ||
| 2 | mean_mention_level |
Relations in the text:
| 2 | {mean,median}_{token,mention,sent,par}_dist |
Chains in the text:
| 2 | chain_ngrams: number of different tri-grams of mentions (each chain been represented by an id) divided by the total number of mentions. For exemple, let there be three chains A, B and C, and the following mentions: AABABCC; the tri-grams are AAB (mention of chain A followed by a mention of chain A followed by a mention of chain B), ABA, etc. See Landragin, Frédéric (2016). |
Lexical diversity of the text:
| 2 | ttr: token type ratio | ||
| 2 | yule_s_k: Yule’s K (Yule, Udny (1944). The Statistical study of Literary Vocabulary. Cambridge University Press.) | ||
| 2 | yule_s_i: Yule’s I (Oakes, Michael (1998). Statistics for Corpus Linguistics. Edingburgh University Press.) |
Complete list of possible values
Please see here to get the values recorded for each fields.
Database formats and other formats
CSV files
The corpora are available in three formats:
The database format is just a zip file containing the csv files for each table, which can be imported into any software (even in Microsfot Excel, some hints on how to use this in Excel may be found here):
mentions.csv
chains.csv
relations.csv
texts.csv
paragraphs.csv
sentences.csv
tokens.csv
CoNLL format
The CoNLL format is a tabular format: each token is on a separate line and annotation for the token are on separate column. Document boundaries are indicated by specific marks, and sentence separation by a white line.
Here is an example:
#begin document <name of the document>
1 Les le DET ... other columns ...
2 singes singe NOUN
3 sont être AUX
4 des un DET
5 mammifères mammifère NOUN
...
1 Bien bien ADV
2 que que SCONJ
3 leur son DET
4 ressemblance ressemblance NOUN
5 avec avec ADP
6 l' le DET
7 Homme homme NOUN
...
#end document
The original CoNLL-2012 (used for the CoNLL-2012 corpus that is not available in this directory because of copyright restrictions) is described in Pradhan et al. (2012), CoNLL-2012 Shared Task: Modeling Multilingual Unrestricted Coreference in OntoNotes. Here is the list of columns (which are separated by any number of spaces):
1. Document ID
2. Part number
3. Word number
4. Word
5. Part of Speech
6. Parse bit
7. Lemma
8. Predicate Frameset ID
9. Word sense
10. Speaker/Author
11. Named Entities
12:N. Predicate Arguments
N. Coreference
For Democrat (the augmented version: dem1921) and Ancor, the list of columns (separated by tabulation) is the list of conll-u augmented with columns for the speaker, the paragraph, the named entity type (2 columns), the coreference. So, in total:
- index of the token in the sentence
- form of the token
- lemma of the token
- universal part-of-speech tag.
- always
_(language-specific part-of-speech tag, not used) - morphological features (see universal dependencies)
- head of the current token (an index of another word or 0 for root)
- universal dependency relation to the head (or
root) (see universal dependencies) - always
_(enhanced dependencies, not used) - always
_(other annotation, not used) - speaker (or
_for Democrat, where no speaker is recorded) - paragraph number
- named entity in the format
(PER * * *)(ex. with 4 tokens) - named entity in the format
(PER PER PER PER)(ex. with 4 tokens) - coreference in conll-2012 style
Jsonlines format
The jsonlines format stores data for several texts (a corpus). Each line is a valid json document, as follows:
{
"clusters": [],
"doc_key": "nw:docname",
"sentences": [["This", "is", "the", "first", "sentence", "."],
["This", "is", "the", "second", "."]],
"speakers": [["spk1", "spk1", "spk1", "spk1", "spk1", "spk1"],
["spk2", "spk2", "spk2", "spk2", "spk2"]]
"pos": [["DET", "V", "DET", "ADJ", "NOUN", "PUNCT"],
["DET", "V", "DET", "ADJ", "PUNCT"]],
...
}
Availability of the corpora
Legal stuff (licenses)
TLDR:
- Democrat: CC BY-SA 4.0,
- Ancor: CC BY-SA-NC 4.0,
- CoNLL: you must download the corpus form the LDC and compile the database yourself.
Democrat
The Democrat corpus is originally distributed on the ortolang plateform. The corpus is distributed under the terms of the "Attribution-ShareAlike 4.0 International" Creative Commons license (CC BY-SA 4.0). So it is allowed to copy and redistribute the corpus, and transform it, as long as it is redistributed under the same conditions (that is, the same license) and the original authors are cited. The original corpus has been developed in the context of the Democrat project, from the French National Research Agency (ANR-15-CE38-0008). The paper that is required to cite is
Frédéric Landragin. Description, modélisation et détection automatique des chaînes de référence (DEMOCRAT). Bulletin de l'Association Française pour l'Intelligence Artificielle, AFIA, 2016, pp.11-15.
The original license, and the license of the modified work I propose, is the CC BY-SA 4.0, which can be read in full here.
Ancor
The Ancor corpus is available on the ortolang.fr plateform (it seems to be restricted to academics working in a French school or university), but also on the corpus website (the link is given on Ortolang), where you can donwload it without restrictions. According to this site, the license is Creative Commons CC-BY-SA-NC for the ESLO part, and Creative Commons CC-BY-SA for the rest. It is the same license as Democrat, except for the Non Commercial part. The legal text of the licences are found here and here. The papers that need to cited are the following ones:
Muzerelle J., Lefeuvre A., Schang E., Antoine J.-Y, Pelletier A., Maurel D., Eshkol I., Villaneau J. 2014. ANCOR-Centre, a Large Free Spoken French Coreference Corpus: description of the Resource and Reliability Measures. LREC'2014, 9th Language Resources and Evaluation Conference
Muzerelle J., Lefeuvre A., Antoine J.-Y., Schang E., Maurel D., Villaneau J., Eshkol I. 2013. ANCOR : premier corpus de français parlé d'envergure annoté en coréférence et distribué librement. Actes TALN'2013.
The modified work is distributed under the terms of the same license as the original work, as required by that very license.
Conll
The CoNLL-2012 corpus is derived from the OntoNotes corpus, which comes with a specific license. The corpus cannot be redistributed, so you will have to compile the database with the scripts I have created (see below).
I just give a sample database built from the trial data from the CoNLL-2012 shared task website. I have masked all the tokens with a [token] string.
Democrat (19th to 21st texts): dem1921
The 19th to 21th-century texts of Democrat (except legal texts), with all the annotations (base, linguistic and advanced, as described above):
- original segmentation with long texts (10k words) uncut, but Wikipedia and press articles cut to their natural boundaries (beginning and end of the text),
- long texts cut from 10k-word to 2k-long segments: this is the corpus used for the LREC paper cited in the introduction.
This subcorpus is available as a relational database, as CoNLL (extended) and as jsonlines.
Democrat (legal texts)
The five legal texts from Democrat have been converted to the CoNLL-2012 format. The original sentence boundaries and part of speech (from TreeTagger) have been kept.
In another version, they have also been parsed with StandfordNLP, but named entities have not been added.
This subcorpus is available as CoNLL-2012 and CoNLL extended formats.
Democrat as a whole
The whole corpus (from 12th to 21st centuries) is available as CoNLL-2012 format, with the original sentence boundaries and part of speech tagging.
Ancor
All the Ancor corpus, with all the annotations (base, linguistic and advanced), computed from the version annotated in the same way as Democrat.
Note that the original documents boundaries have not been kept: the new texts correspond to thematic sections defined by the transcribers of the audio data. Also, the long "sentences" (or rather speech turns, as there are no sentences in Ancor) of more than 100 words have been split at euh interjections.
This is the version used for the LREC paper cited in the introduction.
This corpus is available in the relational database format, as well as CoNLL (extended) and jsonlines.
CoNLL
The CoNLL corpus is based on the OntoNotes corpus, the copyright of which is held by the LDC. You will need to download the corpus from the LDC (which is free but requires you to register and agree to a specifice license), then transform OntoNotes into CoNLL by using the scripts and instructions provided on the CoNLL-2012 shared task website. Then you will need to use the script I provide here.
First concatenate all the documents you want to compute the database for within one file, for example for all the three sets (dev, train, test):
# when you build the data from the conll-2012 website, they are in the `conll-2012` directory
cat path/to/conll-2012/*/data/*/data/english/annotations/*/*/*/*gold_conll > everything.conllRun the setup script:
Then run the db_builder.py script:
python3 db_builder.py --corpus-name conll2012 --linguistic --advanced \
-o db_conll.zip everything.conllIf you have any trouble using the scripts, please contact me through my website.
Compiling the database yourself
First run the setup script, which will download the fasttext filtered word vectors for each corpus:
Then run the db_builder.py script, according to the corpus you want to compile:
# in the `scripts` directory:
# conll
python3 db_builder.py --corpus-name conll2012 --linguistic --advanced \
-o db_conll.zip INPUT.conll
# democrat
python3 db_builder.py --corpus-name dem1921 --linguistic --advanced \
-o /tmp/db_dem1921.zip INPUT.conll
# ancor
python3 db_builder.py --corpus-name ancor --linguistic --advanced \
-o /tmp/db_ancor.zip INPUT.conllThis assumes that you have the INPUT.conll files. For Ancor and Democrat, you can choose one of the conll files from the ancor and democrat directories. For CoNLL, you must build it from the data provided by the LDC and the CoNLL-2012 shared task (see above), or use the trial data.
If you have any trouble using the scripts, please contact me through my website.
Compiling databases for your own texts
You may want to compute a database for your own texts. You may annotate them with an automatic tool such a Standford CoreNLP or manually with a tool like SACR. These tools export to a conll format (use these scripts to convert from SACR to conll). Then run:
(Use --corpus-name conllu for the conll-u format.)
This will create a database with the base annotations (the green circles above). If you data have syntactic parses and named entities, and are like the Democrat corpus, you may add the --linguistic and --advanced options, and change the --corpus-name to dem1921.
License (more legal stuff)
For the scripts (not the corpora): (c) Bruno Oberle 2020, released under the Mozilla Public Licence, version 2.0
If you use the modified corpora:
- Ancor and Demorat are released under Creative Commons licenses (see details above). You must give appropriate credit to the original authors by citing the papers mentionned above and to myself.
- OntoNotes (from which CoNLL is derived) comes with its own license, which you have agreed to when you have downloaded the corpus from the LDC webiste. You must follow it.