Un système de résolution automatique de la coréférence à base de règles linguistiques (mémoire de master)
J'ai deux masters (M2) de l'Université de Strasbourg:
- l'un en Linguistique, Informatique, Traduction (actuellement nommé “Technologies des langues”),
- et l'un en Sciences du langage.
J'ai donc écrit deux mémoires. Cette page résume le premier: ODACR: un Outil de Détection Automatique des Chaînes de Référence à base de règles linguistiques. Pour le second (Étude des chaînes de référence dans les articles de recherche de format IMRaD: problèmes d'annotation, analyse quantitative et qualitative), lire ici.
En plus de l'outil de résolution automatique de la coréférence, j'ai développé deux ressources: un dictionnaire d'entités pour la détection de la coréférence et un diction d'hyperonymes.
Le travail a été publié dans un article scientifique: Détection automatique de chaînes de coréférence pour le français écrit: règles et ressources adaptées au repérage de phénomènes linguistiques spécifiques. Actes des Rencontres des Etudiants Chercheurs en Informatique pour le Traitement Automatique des Langues (TALN-RECITAL), Association française pour l'Intelligence Artificielle, Toulouse, Juillet 2019.
lire le mémoire (135 pages) lire l'article voir le poster
Les deux mémoires portent sur les chaînes de coréférence. Une chaînes de coréférence est l'ensemble de toutes les expressions d'un texte qui renvoient au même référent (expressions référentielles). Par exemple, toutes les expressions en gras dans le texte suivant renvoient à la même entité "Platon":
[Platon] est un philosophe antique de la Grèce classique... [Il] reprit le travail philosophique de certains de [ses] prédécesseurs, notamment Socrate dont [il] fut l'élève (extrait de Wikipédia).
Chaque expression qui fait partie d'une chaîne de référence est appelée une mention.
Dans l'un des travaux, j'ai développé un système de résolution automatique de la coréférence (plus d'informations ci-dessous) à partir de règles linguistiques. Dans le second, j'ai étudié, dans la perspective d'une analyse de corpus, les chaînes de coréférence dans les articles de format IMRaD.
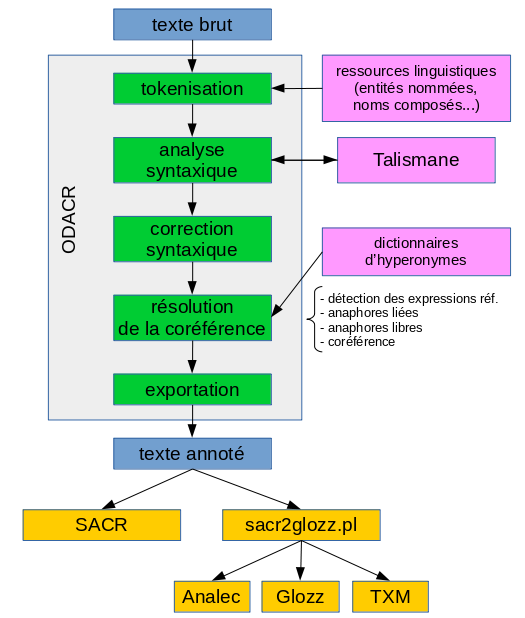
J'ai développé un nouveau système de résolution automatique de la coréférence pour le français écrit. Il est à base de règles et prend en compte des phénomènes linguistiques qui ne sont pas considéré par des systèmes plus orientés vers l'apprentissage automatique (machine learning). Par exemple:
- coréférence des relations nom-nom (et pas seulement les relations nom-pronom) (j'ai construit deux ressources lexicales pour cela, voire ci-dessous):
- avec deux noms communs (ex.: Mon chat... Cet animal...),
- avec deux noms propres (entités nommées) (comme dans Paris... la Ville Lumière),
- avec un nom propre et un nom commun (comme dans La Seine... Ce fleuve);
- groupes (ou listes), comme dans Pierre, Paul and Jacque (cela est fait par une analyse de l'arbre syntaxique de la phrase),
- sujet zéro, comme dans Pierre boit et ø fume (cela est également fait par une analyse de l'arbre syntaxique de la phrase),
- pronoms de première et deuxième personnes dans les citation, comme dans Paul dit: “J'aime le chocolat” (cela est fait en cherchant les guillemets et les verbes déclaratifs).
Les deux ressources lexicales que j'ai construites sont:
D'abord, un dictionnaire d'entités nommées et de noms propres issus de Wikipedia et WordNet, à partir de Yago (chapitre 4.1 du mémoire). Pour chaque entité, on y trouve:
- le type de l'entitée (personne, organisation, lieu, etc.),
- les expressions par lesquelles une entitées peut être désignée (Paris, Ville Lumière...),
- les hyperonymes (Zinedine Zidane: footballeur, sportif, concurrent, homme, etc.) (voir illustration),
- le genre du pronom par lequel l'entité est reprise (par exemple, “Marie Curie” sera reprise par “elle” mais “Pierre Curie” par “il”).

Ensuite, un dictionnaire d'hyperonymes issu du Wiktionnaire (XMLisé par Glawi) (chapitre 4.2 du mémoire). Les définitions commencent généralement par un hyperonyme, selon le sens (cas de polysémie). Par exemple,
- chat: mammifère carnivore félin de taille moyenne...,
- pomme: fruit comestible du pommier...,
- table: meuble composé d'un plateau posé sur un ou plusieurs pieds...
J'ai donc collecté ces hyperonymes et les ai rassemblés en un dictionnaire, par exemple: chat > mammifère > animal > métazoaire. Il y a des restrictions par domaines sémantiques.
J'ai aussi créé des règles pour corriger l'arbre donné par l'analyseur syntaxique que j'ai utilisé (Talismane) (chapitre 5 du mémoire). Cela a été fait après une analyse des erreurs. Par exemple (cliquer pour agrandir):


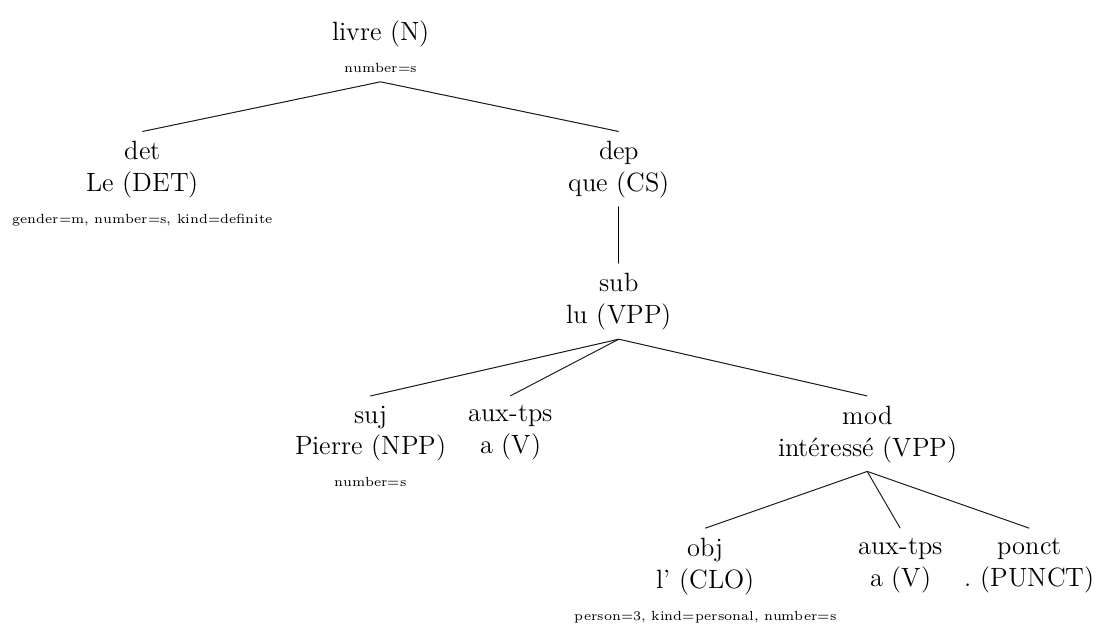
original (sortie de Talismane)
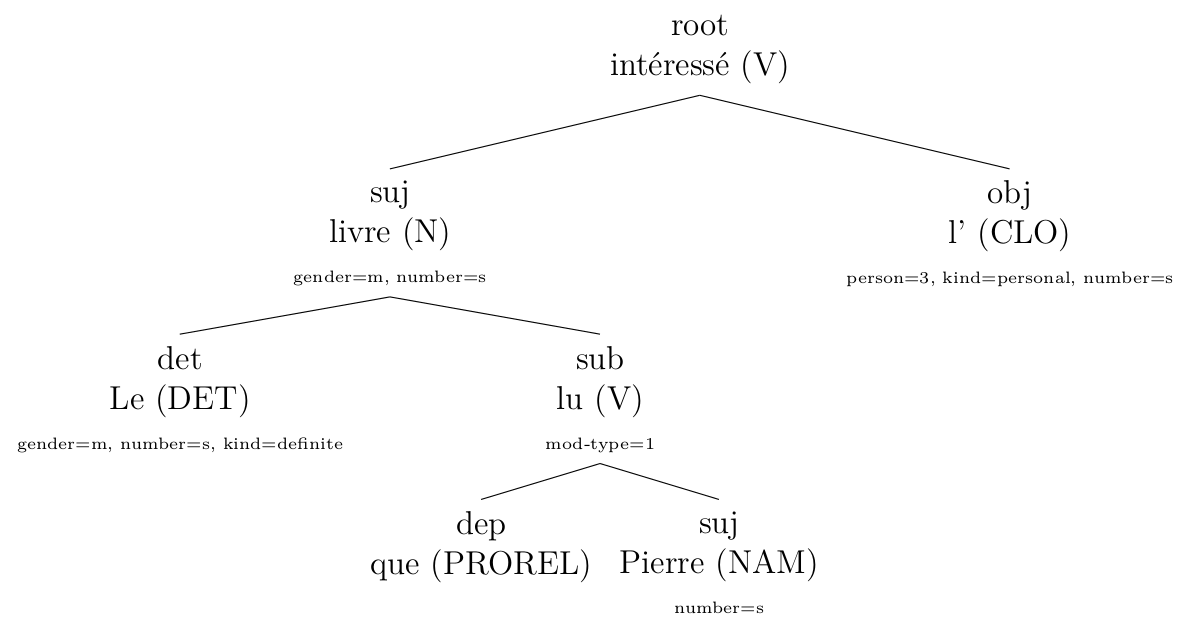
corrigé par mes règles
D'autres règles sont utilisées pour simplifier l'arbre, par exemple pour unifier la représentation des groupes (cliquer pour agrandir):
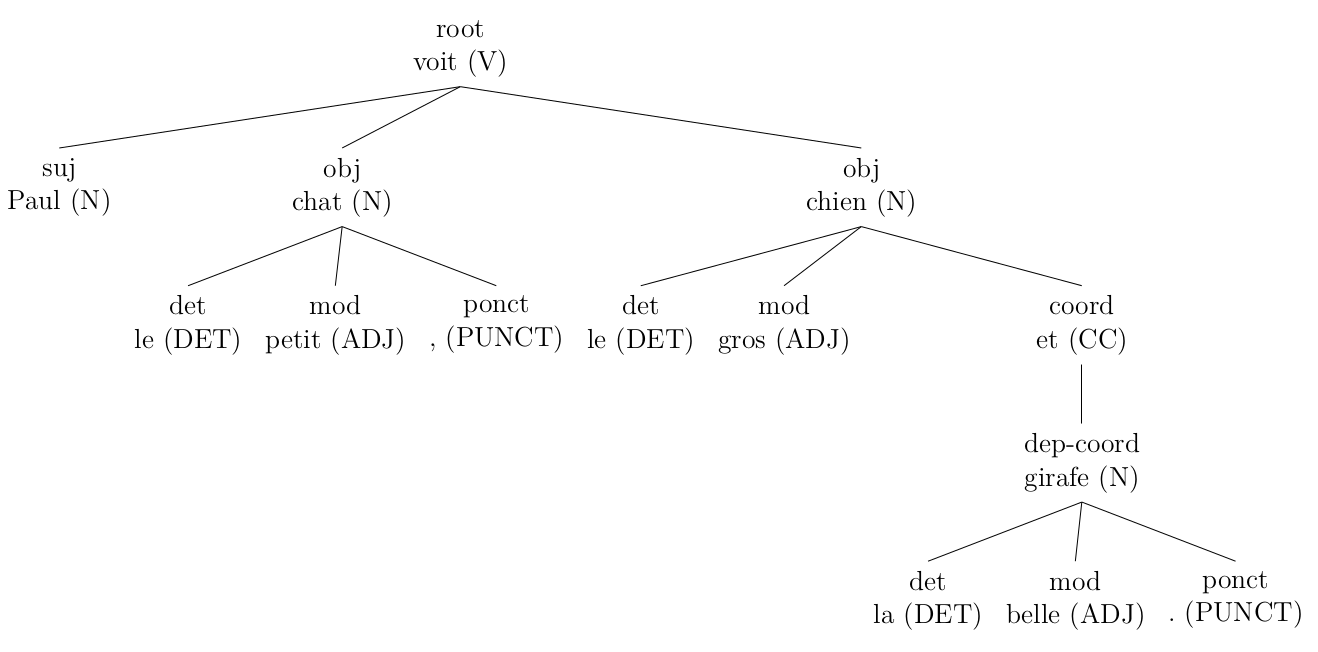
original (sortie de Talismane)
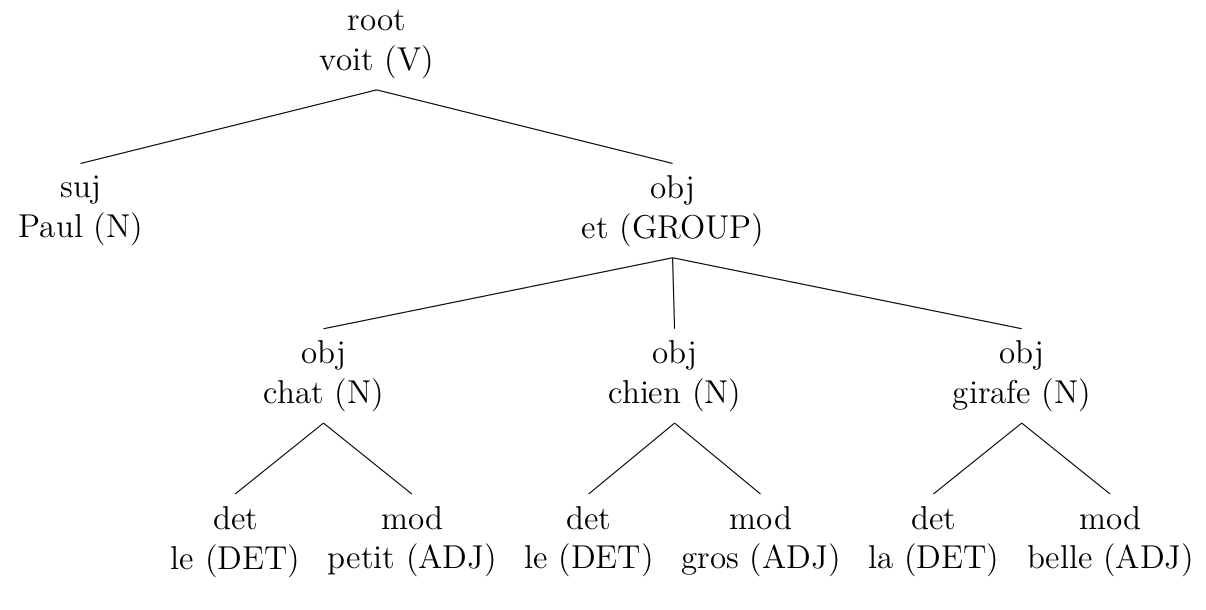
corrigé par mes règles
Ou bien pour diviser les propositions coordonnées ou juxtaposées (cliquer pour agrandir):
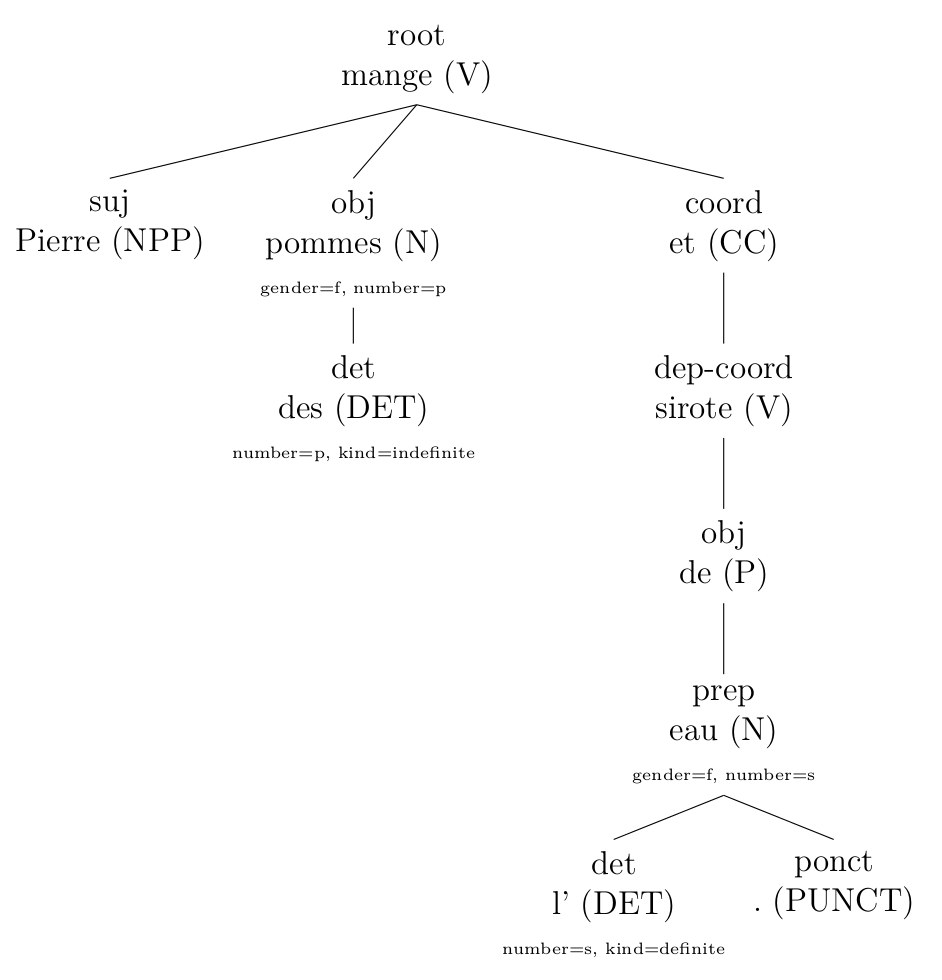
original (sortie de Talismane)
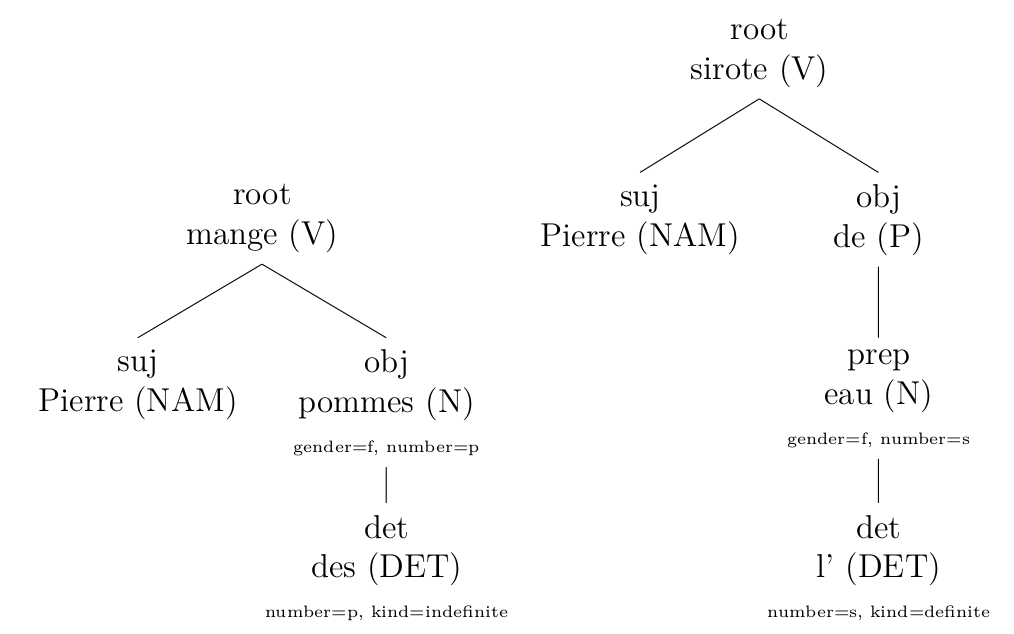
corrigé par mes règles
L'algorithme de résolution de la coréférence en lui-même est un algorithme en plusieurs passes:
- il détecte d'abord les cas d'anaphores où seul des informations syntaxiques sont nécessaires pour trouver l'antécédent, comme les pronoms réfléchis (l'antécédent est le sujet de la proposition), les pronoms relatifs (le nom modifié par la relative), les pronoms détachés (du type moi, je), etc.
- puis les autres anaphores (comme les pronoms personnels), pour lesquelles la découverte de l'antécédent nécessite à la fois des informations syntaxiques et d'autres informations (genre, nombre, discours direct, etc.),
- la coréférence des entités nommées (à partir du dictionnaire d'entités nommées),
- la coréférence des autres noms (à partir du dictionnaire d'hyperonymes et d'information de saillance).
Pour voir l'autre: Étude des chaînes de référence dans les articles de recherche de format IMRaD: problèmes d'annotation, analyse quantitative et qualitative.