Projets
J'aime créer des outils open-source qui me sont utiles (et, espérons-le, à d'autres aussi).
Annotation de données, NLP, conversions entre formats... mais aussi scraping, lecture de médias, applications mobiles, extensions Firefox... jusqu'à la grammaire du grec ancien.
Les technologies que j'utilise sont Python, JavaScript, Go, C, React Native...
D'autres projets sont sur Github .
Outil d'Annotation des Chaînes de Coréférence (SACR)
Un outil pour annoter les mentions et les relations de coréférence à l'aide d'un simple "glisser-déposer".
Optimisé pour faciliter l'annotation, il offre une représentation visuelle des relations, de nombreux raccourcis et des options de recherche.
Prend en charge l'annotation des features de chaque mention, telles que la catégorie grammaticale, le genre grammatical, le nombre, etc. Les annotations sont entièrement personnalisables.
Permet la conversion des annotations vers et depuis divers formats, y compris CoNLL et TXM.
Une "single-page application" développée en JavaScript Vanilla.

Résolution Automatique de la Coréférence pour le Français Parlé et Écrit avec l'IA (cofr)
Un modèle de résolution de coréférence entraîné sur les corpus Ancor et Democrat.
Le modèle détecte les mentions, y compris les singletons, ainsi que les relations de coréférence.
Le modèle est le résultat d'un ajustement fin de BERT, l'un des premiers grands modèles de langage (LLMs). TensorFlow a été utilisé pour le développement.
Ce travail a été publié à LREC 2020.

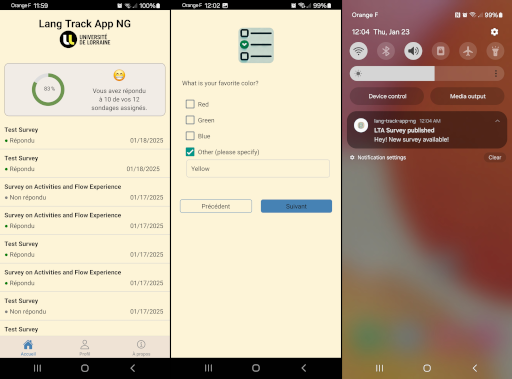
Lang Track App (Next Generation): Une application de sondage
Un projet conçu pour permettre à des chercheurs d'envoyer de petits sondages aux participants via une application mobile et un site web.
Il comprend une application mobile pour Android et iOS, un système back-office et un backend.
Des rappels sont envoyés via des push notifications, des e-mails et/ou des SMS.
Développé en Python, React et React Native.
Actuellement en phase de test.
Scripts de conversion pour divers formats d'annotation de la coréférence (corefconversion)
Une collection de scripts et d'outils pour convertir entre plusieurs formats utilisés dans l'annotation de la coréférence.
Les formats pris en charge incluent CoNLL, Brat, JSONLines, Glozz, SACR, du texte brut, et bien d'autres.
La plupart des scripts sont écrits en Python, avec certains en Perl.
Une partie du script est disponible en tant que packetage PyPI (pip).

Fiches de Linguistique et de Grammaire Grecque (Grec Ancien)
Un ensemble de 150 fiches de référence (environ 420 pages) proposant une description analytique de la morphologie, des temps, des modes, de la phonétique et de la syntaxe du grec ancien.
Elles expliquent en détail les différents cas, à l'aide de schémas.
Je les ai rédigées pendant mes études de grec ancien à l'Université de Strasbourg.
Mon objectif était d'adopter une approche très analytique pour vraiment comprendre les principes sous-jacents. Plutôt que de simplement mémoriser les déclinaisons, ces fiches t'aident à saisir pourquoi les terminaisons sont ce qu'elles sont.
Vinted Downloader (Firefox Extension)
Une extension Firefox pour télécharger des données et des photos en full résolution de l'app Vinted.
Permet de télécharger les données produit aux formats JSON et texte, ainsi que des photos en taille réelle.
Prend également en charge le téléchargement des données de conversation, y compris le contenu, les images en taille réelle et les infos d'expédition et de suivi.
Vinted Downloader (Python package)
Un script Python pour télécharger des données et des photos en full résolution de l'app Vinted.
Télécharge les données produit aux formats JSON et texte, ainsi que les photos en taille réelle.
Permet de télécharger les conversations, y compris le contenu, les images en taille réelle et les données d'expédition et de suivi.
Disponible sur PyPI (pip) et peut être exécuté via la commande vinted-downloader.
Base de données et corpus de coréférence pour l'anglais et le français (corefdb)
Une base de données contenant des données de coréférence (mentions, chaînes et relations) ainsi que des structures textuelles (tokens, phrases, paragraphes et textes), enrichies d'annotations linguistiques (par exemple, catégories grammaticales, entités nommées, etc.).
Il s'agit d'une version améliorée du corpus Democrat pour le français.
Des scripts Python sont disponibles pour créer des bases de données personnalisées à partir d'autres corpus (par exemple, CoNLL ou des annotations fournies par l'utilisateur).
Outil d'Analyse de la Coréférence (CRViewer)
Un outil pour calculer des statistiques de coréférence et les visualiser à l'aide de graphiques.
Écrit en Java. Prend en entrée des fichiers annotés avec SACR.
Supporte d'autres formats d'annotation (p. ex., CoNLL) en passant par une conversion.
Générateur de Données Aléatoires
Un site web pour générer rapidement des éléments aléatoires tels que des noms, des e-mails, des villes, du texte HTML, des images, des emplacements avec cartes, des profils d'utilisateurs, et bien plus encore.
Génère des listes simples ou des structures plus complexes avec des boucles et des groupes.
Toutes les données proviennent de Wikipédia et ont été aléatoirement modifiées.
Visualisation sous forme d'arbres de la sortie d'analyseurs syntaxiques (dependency2tree)
Cet outil convertit la sortie CoNLL de parseurs de dépendances, tels que StanfordNLP (pour l'anglais) ou Talismane (pour le français), en représentations d'arbres LaTeX ou Graphviz.
Rephraise : Utiliser l'IA pour reformuler un texte
Un outil de reformulation de texte, avec des options pour ajuster le niveau de formalité et conserver différents degrés de similarité avec l'original.
La meilleure partie: voir instantanément voir les différences, comme avec un diff GitHub ou GitLab.
Je l'utilise pour peaufiner mes e-mails d'assistance destinés aux clients. 😅
Il envoie simplement les données à l'API d'OpenAI.
Disponible en français et en anglais.
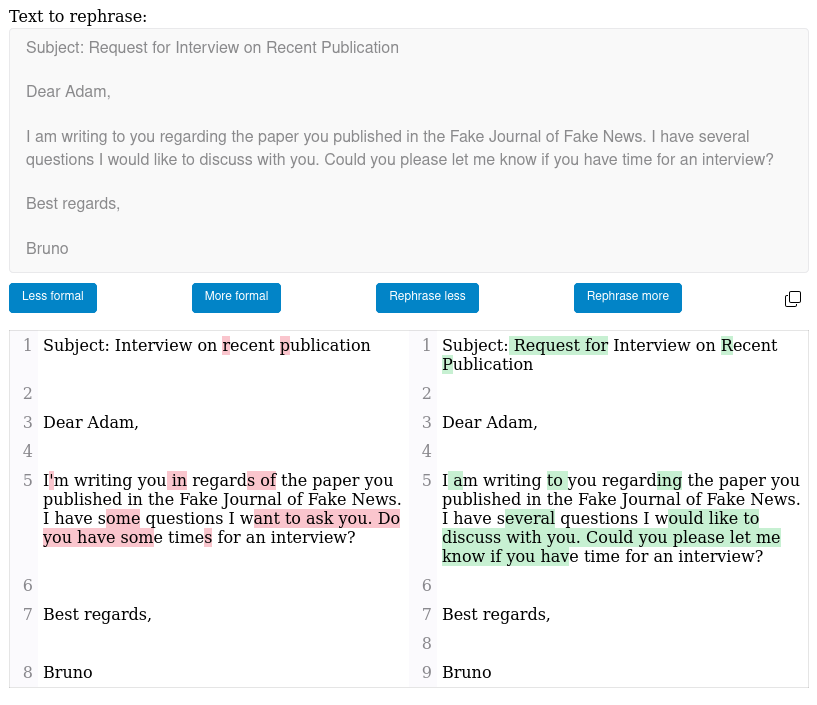
Représentations Visuelles des Relations de Coréférence
Diverses manières de représenter les relations de coréférence entre des expressions linguistiques dans un texte.
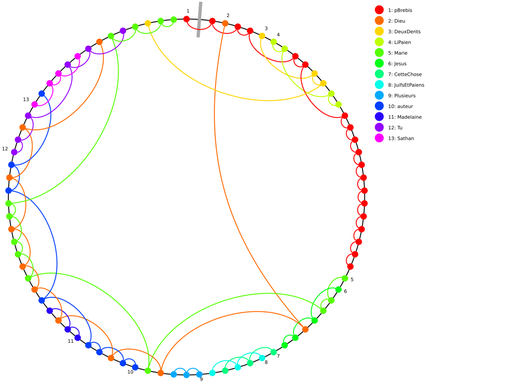
Représentation visuelles de modèle d'élévation de l'USGS et de la NASA (hgt2pnm)
Ce script Python convertit les modèles d'élévation bruts de la NASA et de l'USGS en une image PNM.
Les fichiers HGT contiennent des données d'élévation fournies par l'USGS et la NASA. Chaque pixel représente soit 1 mètre soit 3 mètres, selon la région.
Les données sont fournies sous la forme d'un entier signé 16 bits en ordre d'octets Motorola.
Cet outil convertit les données dans l'ordre d'octets standard de Linux et produit une image.
Afficher un cadre de couleur de l'écran (drawframe)
Un programme qui dessine un cadre apparaissant au-dessus de toutes les autres fenêtres, utile pour l'enregistrement de screencasts.
Cet outil est écrit en C et conçu pour les systèmes Linux utilisant X11.

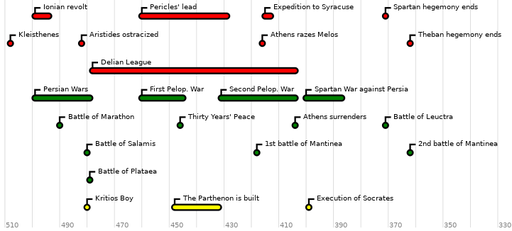
Création de Frises Chronologiques (Timeline) (mktimeline)
Un outil permettant de créer des frises chronologiques visuelles à partir d'une liste de dates et de noms d'événements.
Écrit en Perl 5.
Police de Caractère (Font) pour le Grec Ancien
Une police pour le grec ancien qui ressemble à celle du célèbre éditeur Budé ("Les Belles Lettres"), créée avec FontForge.

Alimentation de Laboratoire Électronique
Comment j'ai réalisé une alimentation de laboratoire (2 × 1.2V to 20V, 333mA).
